diff --git a/.github/workflows/deploy_docs.yml b/.github/workflows/deploy_docs.yml
index 209027caa4..e939baadcd 100644
--- a/.github/workflows/deploy_docs.yml
+++ b/.github/workflows/deploy_docs.yml
@@ -2,7 +2,7 @@ name: Develop Docs
on:
push:
branches: #设置更新哪个分支会更新站点
- - release/3.3
+ - release/3.4
permissions:
contents: write
jobs:
@@ -27,5 +27,5 @@ jobs:
- run: pip install mike mkdocs-material jieba mkdocs-git-revision-date-localized-plugin mkdocs-git-committers-plugin-2 mkdocs-git-authors-plugin mkdocs-static-i18n mkdocs-minify-plugin
- run: |
git fetch origin gh-pages --depth=1
- mike deploy --push --update-aliases 3.3 latest
+ mike deploy --push --update-aliases 3.4 latest
mike set-default --push latest
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index f480361043..ab2e0f7a07 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -72,3 +72,4 @@ repos:
files: ^paddlex/.*\.py$
additional_dependencies:
- stdlib-list==0.10.0
+ - setuptools
diff --git a/deploy/genai_vllm_server_docker/Dockerfile b/deploy/genai_vllm_server_docker/Dockerfile
index 84aa4206fd..f761cc3368 100644
--- a/deploy/genai_vllm_server_docker/Dockerfile
+++ b/deploy/genai_vllm_server_docker/Dockerfile
@@ -4,21 +4,24 @@ RUN apt-get update \
&& apt-get install -y libgl1 \
&& rm -rf /var/lib/apt/lists/*
-ENV PIP_NO_CACHE_DIR=0
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
-RUN python -m pip install torch==2.8.0
+RUN --mount=type=cache,target=/root/.cache/pip \
+ python -m pip install torch==2.8.0
ARG PADDLEX_VERSION=">=3.3.6,<3.4"
-RUN python -m pip install "paddlex${PADDLEX_VERSION}"
+RUN --mount=type=cache,target=/root/.cache/pip \
+ python -m pip install "paddlex${PADDLEX_VERSION}"
ARG BUILD_FOR_SM120=false
-RUN if [ "${BUILD_FOR_SM120}" = 'true' ]; then \
+RUN --mount=type=cache,target=/root/.cache/pip \
+ if [ "${BUILD_FOR_SM120}" = 'true' ]; then \
python -m pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.4.11/flash_attn-2.8.3%2Bcu128torch2.8-cp310-cp310-linux_x86_64.whl; \
else \
python -m pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.3.14/flash_attn-2.8.2+cu128torch2.8-cp310-cp310-linux_x86_64.whl; \
fi \
+ && python -m pip install transformers==4.57.6 \
&& paddlex --install genai-vllm-server
EXPOSE 8080
diff --git a/deploy/hps/sdk/pipelines/OCR/server/model_repo/ocr/1/model.py b/deploy/hps/sdk/pipelines/OCR/server/model_repo/ocr/1/model.py
index 7a99bf9829..1b094662e8 100644
--- a/deploy/hps/sdk/pipelines/OCR/server/model_repo/ocr/1/model.py
+++ b/deploy/hps/sdk/pipelines/OCR/server/model_repo/ocr/1/model.py
@@ -48,6 +48,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -59,6 +60,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -105,12 +108,16 @@ def run_batch(self, inputs, log_ids, batch_id):
ret = executor.map(self._preprocess, inputs_g, log_ids_g)
ind_img_lsts, ind_data_info_lst, ind_visualize_enabled_lst = [], [], []
+ ind_input_id_lst, ind_log_id_lst, ind_input_lst = [], [], []
for i, item in enumerate(ret):
if isinstance(item, tuple):
assert len(item) == 3, len(item)
ind_img_lsts.append(item[0])
ind_data_info_lst.append(item[1])
ind_visualize_enabled_lst.append(item[2])
+ ind_input_id_lst.append(input_ids_g[i])
+ ind_log_id_lst.append(log_ids_g[i])
+ ind_input_lst.append(inputs_g[i])
else:
input_id = input_ids_g[i]
result_or_output_dic[input_id] = item
@@ -146,19 +153,19 @@ def run_batch(self, inputs, log_ids, batch_id):
ind_preds.append(preds[start_idx : start_idx + len(item)])
start_idx += len(item)
- for i, result in zip(
- input_ids_g,
+ for input_id, result in zip(
+ ind_input_id_lst,
executor.map(
self._postprocess,
ind_img_lsts,
ind_data_info_lst,
ind_visualize_enabled_lst,
ind_preds,
- log_ids_g,
- inputs_g,
+ ind_log_id_lst,
+ ind_input_lst,
),
):
- result_or_output_dic[i] = result
+ result_or_output_dic[input_id] = result
assert len(result_or_output_dic) == len(
inputs
@@ -270,6 +277,7 @@ def _postprocess(self, images, data_info, visualize_enabled, preds, log_id, inpu
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/OCR/version.txt b/deploy/hps/sdk/pipelines/OCR/version.txt
index 3a4036fb45..53a75d6735 100644
--- a/deploy/hps/sdk/pipelines/OCR/version.txt
+++ b/deploy/hps/sdk/pipelines/OCR/version.txt
@@ -1 +1 @@
-0.2.5
+0.2.6
diff --git a/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/server/model_repo/chatocr-visual/1/model.py b/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/server/model_repo/chatocr-visual/1/model.py
index 7b2568a7a1..40f7684f15 100644
--- a/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/server/model_repo/chatocr-visual/1/model.py
+++ b/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/server/model_repo/chatocr-visual/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -142,6 +145,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/version.txt b/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/version.txt
index d15723fbe8..1c09c74e22 100644
--- a/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/version.txt
+++ b/deploy/hps/sdk/pipelines/PP-ChatOCRv3-doc/version.txt
@@ -1 +1 @@
-0.3.2
+0.3.3
diff --git a/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/server/model_repo/chatocr-visual/1/model.py b/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/server/model_repo/chatocr-visual/1/model.py
index de0a16bdee..c563ca0823 100644
--- a/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/server/model_repo/chatocr-visual/1/model.py
+++ b/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/server/model_repo/chatocr-visual/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -143,6 +146,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/version.txt b/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/version.txt
index 2b7c5ae018..17b2ccd9bf 100644
--- a/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/version.txt
+++ b/deploy/hps/sdk/pipelines/PP-ChatOCRv4-doc/version.txt
@@ -1 +1 @@
-0.4.2
+0.4.3
diff --git a/deploy/hps/sdk/pipelines/PP-DocTranslation/server/model_repo/doctrans-visual/1/model.py b/deploy/hps/sdk/pipelines/PP-DocTranslation/server/model_repo/doctrans-visual/1/model.py
index 361ce50332..7243078c10 100644
--- a/deploy/hps/sdk/pipelines/PP-DocTranslation/server/model_repo/doctrans-visual/1/model.py
+++ b/deploy/hps/sdk/pipelines/PP-DocTranslation/server/model_repo/doctrans-visual/1/model.py
@@ -30,12 +30,10 @@
class TritonPythonModel(BaseTritonPythonModel):
def initialize(self, args):
super().initialize(args)
-
- self.pipeline.inintial_visual_predictor(self.pipeline.config)
-
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -47,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -151,6 +151,7 @@ def run(self, input, log_id):
filename_template=f"markdown_{i}/{{key}}",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
md_flags = md_data["page_continuation_flags"]
@@ -165,6 +166,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/PP-DocTranslation/version.txt b/deploy/hps/sdk/pipelines/PP-DocTranslation/version.txt
index d917d3e26a..b1e80bb248 100644
--- a/deploy/hps/sdk/pipelines/PP-DocTranslation/version.txt
+++ b/deploy/hps/sdk/pipelines/PP-DocTranslation/version.txt
@@ -1 +1 @@
-0.1.2
+0.1.3
diff --git a/deploy/hps/sdk/pipelines/PP-StructureV3/server/model_repo/layout-parsing/1/model.py b/deploy/hps/sdk/pipelines/PP-StructureV3/server/model_repo/layout-parsing/1/model.py
index f7e8d9b56b..5183d7c62f 100644
--- a/deploy/hps/sdk/pipelines/PP-StructureV3/server/model_repo/layout-parsing/1/model.py
+++ b/deploy/hps/sdk/pipelines/PP-StructureV3/server/model_repo/layout-parsing/1/model.py
@@ -47,6 +47,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -58,6 +59,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -104,12 +107,16 @@ def run_batch(self, inputs, log_ids, batch_id):
ret = executor.map(self._preprocess, inputs_g, log_ids_g)
ind_img_lsts, ind_data_info_lst, ind_visualize_enabled_lst = [], [], []
+ ind_input_ids_lst, ind_log_ids_lst, ind_inputs_lst = [], [], []
for i, item in enumerate(ret):
if isinstance(item, tuple):
assert len(item) == 3, len(item)
ind_img_lsts.append(item[0])
ind_data_info_lst.append(item[1])
ind_visualize_enabled_lst.append(item[2])
+ ind_input_ids_lst.append(input_ids_g[i])
+ ind_log_ids_lst.append(log_ids_g[i])
+ ind_inputs_lst.append(inputs_g[i])
else:
input_id = input_ids_g[i]
result_or_output_dic[input_id] = item
@@ -179,19 +186,19 @@ def run_batch(self, inputs, log_ids, batch_id):
ind_preds.append(preds[start_idx : start_idx + len(item)])
start_idx += len(item)
- for i, result in zip(
- input_ids_g,
+ for input_id, result in zip(
+ ind_input_ids_lst,
executor.map(
self._postprocess,
ind_img_lsts,
ind_data_info_lst,
ind_visualize_enabled_lst,
ind_preds,
- log_ids_g,
- inputs_g,
+ ind_log_ids_lst,
+ ind_inputs_lst,
),
):
- result_or_output_dic[i] = result
+ result_or_output_dic[input_id] = result
assert len(result_or_output_dic) == len(
inputs
@@ -323,6 +330,7 @@ def _postprocess(self, images, data_info, visualize_enabled, preds, log_id, inpu
filename_template=f"markdown_{i}/{{key}}",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
md_flags = md_data["page_continuation_flags"]
@@ -337,6 +345,7 @@ def _postprocess(self, images, data_info, visualize_enabled, preds, log_id, inpu
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/PP-StructureV3/version.txt b/deploy/hps/sdk/pipelines/PP-StructureV3/version.txt
index c2c0004f0e..449d7e73a9 100644
--- a/deploy/hps/sdk/pipelines/PP-StructureV3/version.txt
+++ b/deploy/hps/sdk/pipelines/PP-StructureV3/version.txt
@@ -1 +1 @@
-0.3.5
+0.3.6
diff --git a/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/model_repo/layout-parsing/1/model.py b/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/model_repo/layout-parsing/1/model.py
index f0b0a64ac3..6192a312d0 100644
--- a/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/model_repo/layout-parsing/1/model.py
+++ b/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/model_repo/layout-parsing/1/model.py
@@ -47,6 +47,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -58,6 +59,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -104,12 +107,16 @@ def run_batch(self, inputs, log_ids, batch_id):
ret = executor.map(self._preprocess, inputs_g, log_ids_g)
ind_img_lsts, ind_data_info_lst, ind_visualize_enabled_lst = [], [], []
+ ind_input_id_lst, ind_log_id_lst, ind_input_lst = [], [], []
for i, item in enumerate(ret):
if isinstance(item, tuple):
assert len(item) == 3, len(item)
ind_img_lsts.append(item[0])
ind_data_info_lst.append(item[1])
ind_visualize_enabled_lst.append(item[2])
+ ind_input_id_lst.append(input_ids_g[i])
+ ind_log_id_lst.append(log_ids_g[i])
+ ind_input_lst.append(inputs_g[i])
else:
input_id = input_ids_g[i]
result_or_output_dic[input_id] = item
@@ -157,19 +164,19 @@ def run_batch(self, inputs, log_ids, batch_id):
ind_preds.append(preds[start_idx : start_idx + len(item)])
start_idx += len(item)
- for i, result in zip(
- input_ids_g,
+ for input_id, result in zip(
+ ind_input_id_lst,
executor.map(
self._postprocess,
ind_img_lsts,
ind_data_info_lst,
ind_visualize_enabled_lst,
ind_preds,
- log_ids_g,
- inputs_g,
+ ind_log_id_lst,
+ ind_input_lst,
),
):
- result_or_output_dic[i] = result
+ result_or_output_dic[input_id] = result
assert len(result_or_output_dic) == len(
inputs
@@ -301,6 +308,7 @@ def _postprocess(self, images, data_info, visualize_enabled, preds, log_id, inpu
filename_template=f"markdown_{i}/{{key}}",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
if visualize_enabled:
@@ -314,6 +322,7 @@ def _postprocess(self, images, data_info, visualize_enabled, preds, log_id, inpu
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/pipeline_config.yaml b/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/pipeline_config.yaml
index ebf5804d29..900892f522 100644
--- a/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/pipeline_config.yaml
+++ b/deploy/hps/sdk/pipelines/PaddleOCR-VL/server/pipeline_config.yaml
@@ -103,3 +103,7 @@ SubPipelines:
module_name: image_unwarping
model_name: UVDoc
model_dir: null
+
+Serving:
+ extra:
+ max_num_input_imgs: null
diff --git a/deploy/hps/sdk/pipelines/PaddleOCR-VL/version.txt b/deploy/hps/sdk/pipelines/PaddleOCR-VL/version.txt
index 0ea3a944b3..9e11b32fca 100644
--- a/deploy/hps/sdk/pipelines/PaddleOCR-VL/version.txt
+++ b/deploy/hps/sdk/pipelines/PaddleOCR-VL/version.txt
@@ -1 +1 @@
-0.2.0
+0.3.1
diff --git a/deploy/hps/sdk/pipelines/doc_preprocessor/server/model_repo/document-preprocessing/1/model.py b/deploy/hps/sdk/pipelines/doc_preprocessor/server/model_repo/document-preprocessing/1/model.py
index 629dd34e1a..390ac1a1d1 100644
--- a/deploy/hps/sdk/pipelines/doc_preprocessor/server/model_repo/document-preprocessing/1/model.py
+++ b/deploy/hps/sdk/pipelines/doc_preprocessor/server/model_repo/document-preprocessing/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -131,6 +134,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/doc_preprocessor/version.txt b/deploy/hps/sdk/pipelines/doc_preprocessor/version.txt
index 0c62199f16..ee1372d33a 100644
--- a/deploy/hps/sdk/pipelines/doc_preprocessor/version.txt
+++ b/deploy/hps/sdk/pipelines/doc_preprocessor/version.txt
@@ -1 +1 @@
-0.2.1
+0.2.2
diff --git a/deploy/hps/sdk/pipelines/formula_recognition/server/model_repo/formula-recognition/1/model.py b/deploy/hps/sdk/pipelines/formula_recognition/server/model_repo/formula-recognition/1/model.py
index 7af06c405a..0ccc35d1de 100644
--- a/deploy/hps/sdk/pipelines/formula_recognition/server/model_repo/formula-recognition/1/model.py
+++ b/deploy/hps/sdk/pipelines/formula_recognition/server/model_repo/formula-recognition/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -128,6 +131,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/formula_recognition/version.txt b/deploy/hps/sdk/pipelines/formula_recognition/version.txt
index 0c62199f16..ee1372d33a 100644
--- a/deploy/hps/sdk/pipelines/formula_recognition/version.txt
+++ b/deploy/hps/sdk/pipelines/formula_recognition/version.txt
@@ -1 +1 @@
-0.2.1
+0.2.2
diff --git a/deploy/hps/sdk/pipelines/layout_parsing/server/model_repo/layout-parsing/1/model.py b/deploy/hps/sdk/pipelines/layout_parsing/server/model_repo/layout-parsing/1/model.py
index b4ba08c961..e96a2f6f55 100644
--- a/deploy/hps/sdk/pipelines/layout_parsing/server/model_repo/layout-parsing/1/model.py
+++ b/deploy/hps/sdk/pipelines/layout_parsing/server/model_repo/layout-parsing/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -143,6 +146,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/layout_parsing/version.txt b/deploy/hps/sdk/pipelines/layout_parsing/version.txt
index 9e11b32fca..d15723fbe8 100644
--- a/deploy/hps/sdk/pipelines/layout_parsing/version.txt
+++ b/deploy/hps/sdk/pipelines/layout_parsing/version.txt
@@ -1 +1 @@
-0.3.1
+0.3.2
diff --git a/deploy/hps/sdk/pipelines/seal_recognition/server/model_repo/seal-recognition/1/model.py b/deploy/hps/sdk/pipelines/seal_recognition/server/model_repo/seal-recognition/1/model.py
index 4885f6a68c..ee41cd35b3 100644
--- a/deploy/hps/sdk/pipelines/seal_recognition/server/model_repo/seal-recognition/1/model.py
+++ b/deploy/hps/sdk/pipelines/seal_recognition/server/model_repo/seal-recognition/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -134,6 +137,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/seal_recognition/version.txt b/deploy/hps/sdk/pipelines/seal_recognition/version.txt
index ee1372d33a..7179039691 100644
--- a/deploy/hps/sdk/pipelines/seal_recognition/version.txt
+++ b/deploy/hps/sdk/pipelines/seal_recognition/version.txt
@@ -1 +1 @@
-0.2.2
+0.2.3
diff --git a/deploy/hps/sdk/pipelines/table_recognition/server/model_repo/table-recognition/1/model.py b/deploy/hps/sdk/pipelines/table_recognition/server/model_repo/table-recognition/1/model.py
index c1624046bb..baaafe4d4e 100644
--- a/deploy/hps/sdk/pipelines/table_recognition/server/model_repo/table-recognition/1/model.py
+++ b/deploy/hps/sdk/pipelines/table_recognition/server/model_repo/table-recognition/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -132,6 +135,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/table_recognition/version.txt b/deploy/hps/sdk/pipelines/table_recognition/version.txt
index 267577d47e..2b7c5ae018 100644
--- a/deploy/hps/sdk/pipelines/table_recognition/version.txt
+++ b/deploy/hps/sdk/pipelines/table_recognition/version.txt
@@ -1 +1 @@
-0.4.1
+0.4.2
diff --git a/deploy/hps/sdk/pipelines/table_recognition_v2/server/model_repo/table-recognition/1/model.py b/deploy/hps/sdk/pipelines/table_recognition_v2/server/model_repo/table-recognition/1/model.py
index 508981080b..552bf3b5ef 100644
--- a/deploy/hps/sdk/pipelines/table_recognition_v2/server/model_repo/table-recognition/1/model.py
+++ b/deploy/hps/sdk/pipelines/table_recognition_v2/server/model_repo/table-recognition/1/model.py
@@ -33,6 +33,7 @@ def initialize(self, args):
self.context = {}
self.context["file_storage"] = None
self.context["return_img_urls"] = False
+ self.context["url_expires_in"] = -1
self.context["max_num_input_imgs"] = _DEFAULT_MAX_NUM_INPUT_IMGS
self.context["max_output_img_size"] = _DEFAULT_MAX_OUTPUT_IMG_SIZE
if self.app_config.extra:
@@ -44,6 +45,8 @@ def initialize(self, args):
self.context["return_img_urls"] = self.app_config.extra[
"return_img_urls"
]
+ if "url_expires_in" in self.app_config.extra:
+ self.context["url_expires_in"] = self.app_config.extra["url_expires_in"]
if "max_num_input_imgs" in self.app_config.extra:
self.context["max_num_input_imgs"] = self.app_config.extra[
"max_num_input_imgs"
@@ -137,6 +140,7 @@ def run(self, input, log_id):
filename_template=f"{{key}}_{i}.jpg",
file_storage=self.context["file_storage"],
return_urls=self.context["return_img_urls"],
+ url_expires_in=self.context["url_expires_in"],
max_img_size=self.context["max_output_img_size"],
)
else:
diff --git a/deploy/hps/sdk/pipelines/table_recognition_v2/version.txt b/deploy/hps/sdk/pipelines/table_recognition_v2/version.txt
index 267577d47e..2b7c5ae018 100644
--- a/deploy/hps/sdk/pipelines/table_recognition_v2/version.txt
+++ b/deploy/hps/sdk/pipelines/table_recognition_v2/version.txt
@@ -1 +1 @@
-0.4.1
+0.4.2
diff --git a/deploy/hps/server_env/cpu_version.txt b/deploy/hps/server_env/cpu_version.txt
index e4737652ca..0b69c00c5f 100644
--- a/deploy/hps/server_env/cpu_version.txt
+++ b/deploy/hps/server_env/cpu_version.txt
@@ -1 +1 @@
-0.3.13
+0.3.14
diff --git a/deploy/hps/server_env/gpu_version.txt b/deploy/hps/server_env/gpu_version.txt
index 0b69c00c5f..9e29e10619 100644
--- a/deploy/hps/server_env/gpu_version.txt
+++ b/deploy/hps/server_env/gpu_version.txt
@@ -1 +1 @@
-0.3.14
+0.3.15
diff --git a/deploy/hps/server_env/paddlex-hps-server/pyproject.toml b/deploy/hps/server_env/paddlex-hps-server/pyproject.toml
index 5d85392841..f6dcad64a4 100644
--- a/deploy/hps/server_env/paddlex-hps-server/pyproject.toml
+++ b/deploy/hps/server_env/paddlex-hps-server/pyproject.toml
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
[project]
name = "paddlex-hps-server"
-version = "0.4.0"
+version = "0.5.0"
# `paddlex` is not included here
dependencies = [
"colorlog >= 6.9",
diff --git a/deploy/hps/server_env/paddlex-hps-server/src/paddlex_hps_server/app_common.py b/deploy/hps/server_env/paddlex-hps-server/src/paddlex_hps_server/app_common.py
index 14f699c3f1..6250706821 100644
--- a/deploy/hps/server_env/paddlex-hps-server/src/paddlex_hps_server/app_common.py
+++ b/deploy/hps/server_env/paddlex-hps-server/src/paddlex_hps_server/app_common.py
@@ -46,6 +46,7 @@ def postprocess_image(
*,
file_storage: Optional[Storage] = None,
return_url: bool = False,
+ url_expires_in: int = -1,
max_img_size: Optional[Tuple[int, int]] = None,
) -> str:
if return_url:
@@ -71,7 +72,7 @@ def postprocess_image(
file_storage.set(key, img_bytes)
if return_url:
assert isinstance(file_storage, SupportsGetURL)
- return file_storage.get_url(key)
+ return file_storage.get_url(key, expires_in=url_expires_in)
return utils.base64_encode(img_bytes)
@@ -81,6 +82,7 @@ def postprocess_images(
filename_template: str = "{key}.jpg",
file_storage: Optional[Storage] = None,
return_urls: bool = False,
+ url_expires_in: int = -1,
max_img_size: Optional[Tuple[int, int]] = None,
) -> Dict[str, str]:
output_images: Dict[str, str] = {}
@@ -95,6 +97,7 @@ def postprocess_images(
filename=filename_template.format(key=key),
file_storage=file_storage,
return_url=return_urls,
+ url_expires_in=url_expires_in,
max_img_size=max_img_size,
)
return output_images
diff --git a/deploy/hps/server_env/requirements/cpu.txt b/deploy/hps/server_env/requirements/cpu.txt
index c24a8fc5af..a3acfe3055 100644
--- a/deploy/hps/server_env/requirements/cpu.txt
+++ b/deploy/hps/server_env/requirements/cpu.txt
@@ -161,7 +161,9 @@ langchain-core==0.2.43
langchain-openai==0.1.25
# via paddlex (../../../setup.py)
langchain-text-splitters==0.2.4
- # via langchain
+ # via
+ # langchain
+ # paddlex (../../../setup.py)
langsmith==0.1.147
# via
# langchain
@@ -345,6 +347,7 @@ scikit-learn==1.6.1
# via paddlex (../../../setup.py)
scipy==1.15.2
# via
+ # paddlex (../../../setup.py)
# scikit-image
# scikit-learn
sentencepiece==0.2.1
diff --git a/deploy/hps/server_env/requirements/gpu.txt b/deploy/hps/server_env/requirements/gpu.txt
index caa9a8fbc0..e43d89b38f 100644
--- a/deploy/hps/server_env/requirements/gpu.txt
+++ b/deploy/hps/server_env/requirements/gpu.txt
@@ -161,7 +161,9 @@ langchain-core==0.2.43
langchain-openai==0.1.25
# via paddlex (../../../setup.py)
langchain-text-splitters==0.2.4
- # via langchain
+ # via
+ # langchain
+ # paddlex (../../../setup.py)
langsmith==0.1.147
# via
# langchain
@@ -345,6 +347,7 @@ scikit-learn==1.6.1
# via paddlex (../../../setup.py)
scipy==1.15.2
# via
+ # paddlex (../../../setup.py)
# scikit-image
# scikit-learn
sentencepiece==0.2.1
diff --git a/deploy/hps/server_env/scripts/remove_images.sh b/deploy/hps/server_env/scripts/remove_images.sh
index 2926504e3d..2b89b756f3 100755
--- a/deploy/hps/server_env/scripts/remove_images.sh
+++ b/deploy/hps/server_env/scripts/remove_images.sh
@@ -6,6 +6,6 @@ for device_type in 'gpu' 'cpu'; do
version="$(cat "${device_type}_version.txt")"
docker rmi \
"ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex${paddlex_version%.*}-${device_type}" \
- "ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:${version}-${device_type}" \
+ "ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:${version}-paddlex${paddlex_version}-${device_type}" \
"ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:latest-${device_type}"
done
diff --git a/docs/pipeline_usage/tutorials/ocr_pipelines/PP-DocTranslation.en.md b/docs/pipeline_usage/tutorials/ocr_pipelines/PP-DocTranslation.en.md
index ae97468e26..5871215719 100644
--- a/docs/pipeline_usage/tutorials/ocr_pipelines/PP-DocTranslation.en.md
+++ b/docs/pipeline_usage/tutorials/ocr_pipelines/PP-DocTranslation.en.md
@@ -1590,9 +1590,7 @@ The following is the API reference for basic Serving and examples of multilingua
file |
string |
-The URL of an image file or PDF file accessible by the server, or the Base64-encoded result of the content of the aforementioned file types. By default, for PDF files with more than 10 pages, only the first 10 pages will be processed.
To remove the page limit, add the following configuration to the pipeline configuration file:Serving:
- extra:
- max_num_input_imgs: null
+ | The URL of an image file or PDF file accessible by the server, or the Base64-encoded result of the content of the aforementioned file types.
|
Yes |
diff --git a/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.en.md b/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.en.md
index bcac347f89..e312cf733d 100644
--- a/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.en.md
+++ b/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.en.md
@@ -6,7 +6,7 @@ comments: true
PaddleOCR-VL is a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
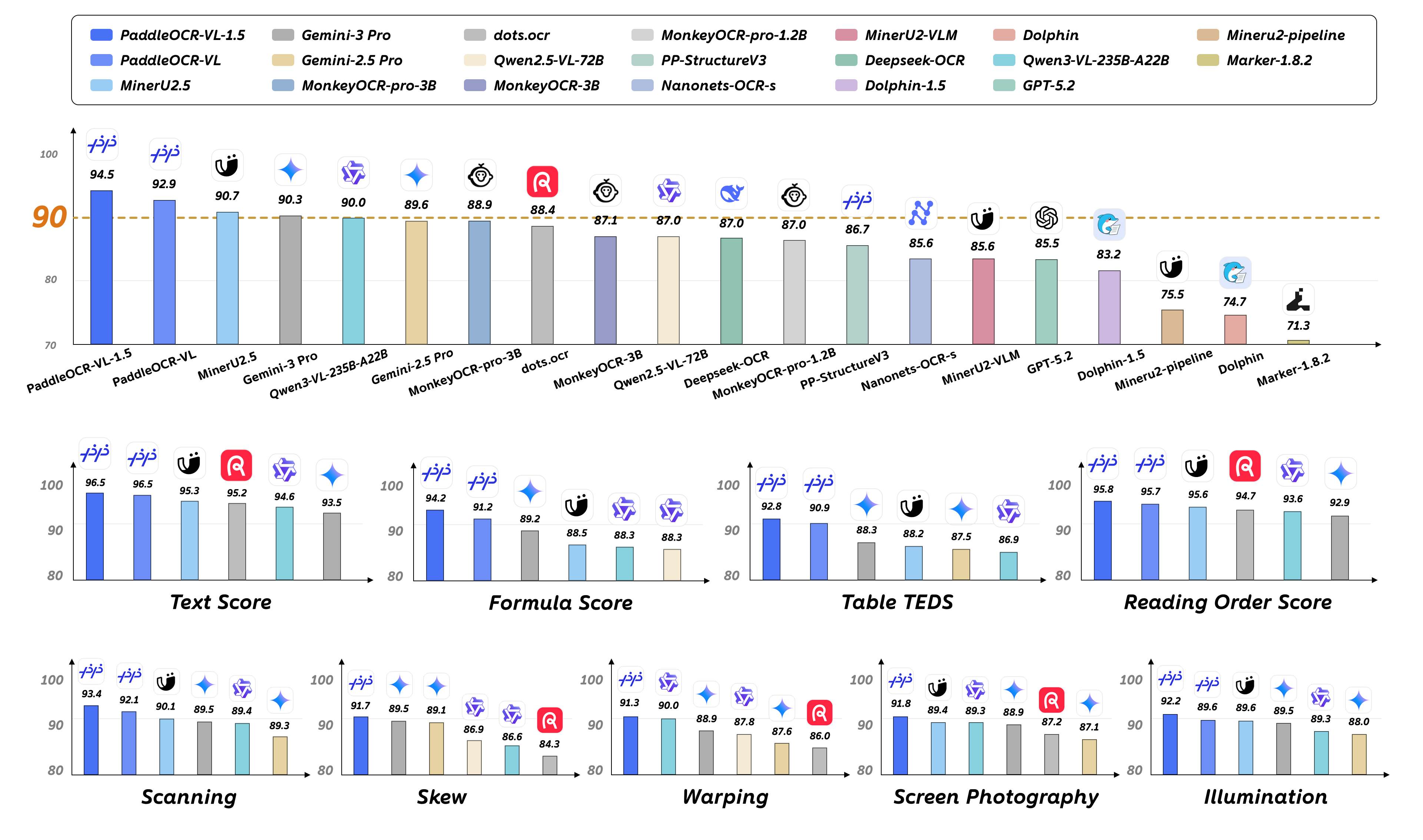
-On January 29, 2026, we released PaddleOCR-VL-1.5. PaddleOCR-VL-1.5 not only significantly improved the accuracy on the OmniDocBench v1.5 evaluation set to 94.5%, but also innovatively supports irregular-shaped bounding box localization. As a result, PaddleOCR-VL-1.5 demonstrates outstanding performance in real-world scenarios such as Skew, Warping, Screen Photography, Illumination, and Scanning. In addition, the model has added new capabilities for seal (stamp) recognition and text detection and recognition, with key metrics continuing to lead the industry.
+**On January 29, 2026, we released PaddleOCR-VL-1.5. PaddleOCR-VL-1.5 not only significantly improved the accuracy on the OmniDocBench v1.5 evaluation set to 94.5%, but also innovatively supports irregular-shaped bounding box localization. As a result, PaddleOCR-VL-1.5 demonstrates outstanding performance in real-world scenarios such as Skew, Warping, Screen Photography, Illumination, and Scanning. In addition, the model has added new capabilities for seal (stamp) recognition and text detection and recognition, with key metrics continuing to lead the industry.**
 @@ -1364,9 +1364,7 @@ Below are the API references for basic service-based deployment and examples of
@@ -1364,9 +1364,7 @@ Below are the API references for basic service-based deployment and examples of
file |
string |
-The URL of an image file or PDF file accessible to the server, or the Base64-encoded result of the content of the aforementioned file types. By default, for PDF files with more than 10 pages, only the first 10 pages will be processed.
To remove the page limit, add the following configuration to the production line configuration file: Serving:
- extra:
- max_num_input_imgs: null
+ | The URL of an image file or PDF file accessible to the server, or the Base64-encoded result of the content of the aforementioned file types.
|
Yes |
diff --git a/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.md b/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.md
index 1213104491..960a0bbe51 100644
--- a/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.md
+++ b/docs/pipeline_usage/tutorials/ocr_pipelines/PaddleOCR-VL.md
@@ -6,7 +6,7 @@ comments: true
PaddleOCR-VL 是一款先进、高效的文档解析模型,专为文档中的元素识别设计。其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公开基准与内部基准上的全面评测,PaddleOCR-VL 在页级级文档解析与元素级识别均达到 SOTA 表现。它显著优于现有的基于Pipeline方案和文档解析多模态方案以及先进的通用多模态大模型,并具备更快的推理速度。这些优势使其非常适合在真实场景中落地部署。
-2026年1月29日,我们发布了PaddleOCR-VL-1.5。PaddleOCR-VL-1.5不仅以94.5%精度大幅刷新了评测集OmniDocBench v1.5,更创新性地支持了异形框定位,使得PaddleOCR-VL-1.5 在扫描、倾斜、弯折、屏幕拍摄及复杂光照等真实场景中均表现优异。此外,模型还新增了印章识别与文本检测识别能力,关键指标持续领跑。
+**2026年1月29日,我们发布了PaddleOCR-VL-1.5。PaddleOCR-VL-1.5不仅以94.5%精度大幅刷新了评测集OmniDocBench v1.5,更创新性地支持了异形框定位,使得PaddleOCR-VL-1.5 在扫描、倾斜、弯折、屏幕拍摄及复杂光照等真实场景中均表现优异。此外,模型还新增了印章识别与文本检测识别能力,关键指标持续领跑。**
@@ -1551,7 +1551,7 @@ INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
mergeTables |
boolean |
-请参阅PaddleOCR-VL对象中 restructure_pages 方法的 merge_table 参数相关说明。仅当restructurePages为true时生效。 |
+请参阅PaddleOCR-VL对象中 restructure_pages 方法的 merge_tables 参数相关说明。仅当restructurePages为true时生效。 |
否 |
diff --git a/paddlex/.version b/paddlex/.version
index 18091983f5..4d9d11cf50 100644
--- a/paddlex/.version
+++ b/paddlex/.version
@@ -1 +1 @@
-3.4.0
+3.4.2
diff --git a/paddlex/configs/pipelines/PaddleOCR-VL-1.5.yaml b/paddlex/configs/pipelines/PaddleOCR-VL-1.5.yaml
index 17aca18f1d..e49cef34e3 100644
--- a/paddlex/configs/pipelines/PaddleOCR-VL-1.5.yaml
+++ b/paddlex/configs/pipelines/PaddleOCR-VL-1.5.yaml
@@ -59,7 +59,7 @@ SubModules:
module_name: vl_recognition
model_name: PaddleOCR-VL-1.5-0.9B
model_dir: null
- batch_size: 4096
+ batch_size: -1
genai_config:
backend: native
@@ -79,3 +79,7 @@ SubPipelines:
module_name: image_unwarping
model_name: UVDoc
model_dir: null
+
+Serving:
+ extra:
+ max_num_input_imgs: null
diff --git a/paddlex/configs/pipelines/PaddleOCR-VL.yaml b/paddlex/configs/pipelines/PaddleOCR-VL.yaml
index fdb52c7ede..900892f522 100644
--- a/paddlex/configs/pipelines/PaddleOCR-VL.yaml
+++ b/paddlex/configs/pipelines/PaddleOCR-VL.yaml
@@ -83,7 +83,7 @@ SubModules:
module_name: vl_recognition
model_name: PaddleOCR-VL-0.9B
model_dir: null
- batch_size: 4096
+ batch_size: -1
genai_config:
backend: native
@@ -103,3 +103,7 @@ SubPipelines:
module_name: image_unwarping
model_name: UVDoc
model_dir: null
+
+Serving:
+ extra:
+ max_num_input_imgs: null
diff --git a/paddlex/inference/common/batch_sampler/image_batch_sampler.py b/paddlex/inference/common/batch_sampler/image_batch_sampler.py
index dd78354fe7..c519765f69 100644
--- a/paddlex/inference/common/batch_sampler/image_batch_sampler.py
+++ b/paddlex/inference/common/batch_sampler/image_batch_sampler.py
@@ -20,6 +20,7 @@
from ....utils import logging
from ....utils.cache import CACHE_DIR
from ....utils.download import download
+from ....utils.flags import PDF_RENDER_SCALE
from ...utils.io import PDFReader
from .base_batch_sampler import BaseBatchSampler, Batch
@@ -48,7 +49,7 @@ class ImageBatchSampler(BaseBatchSampler):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
- self.pdf_reader = PDFReader()
+ self.pdf_reader = PDFReader(zoom=PDF_RENDER_SCALE)
# XXX: auto download for url
def _download_from_url(self, in_path):
diff --git a/paddlex/inference/genai/configs/paddleocr_vl_09b.py b/paddlex/inference/genai/configs/paddleocr_vl_09b.py
index 5451bf6e25..9ecfde414a 100644
--- a/paddlex/inference/genai/configs/paddleocr_vl_09b.py
+++ b/paddlex/inference/genai/configs/paddleocr_vl_09b.py
@@ -45,13 +45,26 @@ def get_config(backend):
cfg["max-concurrency"] = 2048
return cfg
elif backend == "vllm":
- return {
- "trust-remote-code": True,
- "gpu-memory-utilization": 0.5,
- "max-model-len": 16384,
- "max-num-batched-tokens": 131072,
- "api-server-count": 4,
- }
+ require_deps("torch")
+
+ import torch
+
+ if torch.xpu.is_available():
+ return {
+ "trust-remote-code": True,
+ "max-num-batched-tokens": 16384,
+ "no-enable-prefix-caching": True,
+ "mm-processor-cache-gb": 0,
+ "enforce-eager": True,
+ }
+ else:
+ return {
+ "trust-remote-code": True,
+ "gpu-memory-utilization": 0.5,
+ "max-model-len": 16384,
+ "max-num-batched-tokens": 131072,
+ "api-server-count": 4,
+ }
elif backend == "sglang":
return {
"trust-remote-code": True,
diff --git a/paddlex/inference/models/common/genai.py b/paddlex/inference/models/common/genai.py
index 9a6d2edbcf..d5a10d764f 100644
--- a/paddlex/inference/models/common/genai.py
+++ b/paddlex/inference/models/common/genai.py
@@ -29,12 +29,18 @@
"vllm-server",
"sglang-server",
"mlx-vlm-server",
+ "llama-cpp-server",
]
class GenAIConfig(BaseModel):
backend: Literal[
- "native", "fastdeploy-server", "vllm-server", "sglang-server", "mlx-vlm-server"
+ "native",
+ "fastdeploy-server",
+ "vllm-server",
+ "sglang-server",
+ "mlx-vlm-server",
+ "llama-cpp-server",
] = "native"
server_url: Optional[str] = None
max_concurrency: int = 200
diff --git a/paddlex/inference/models/common/static_infer.py b/paddlex/inference/models/common/static_infer.py
index 4e0556c829..3b4de0518e 100644
--- a/paddlex/inference/models/common/static_infer.py
+++ b/paddlex/inference/models/common/static_infer.py
@@ -401,7 +401,13 @@ def _create(
if hasattr(config, "enable_new_executor"):
config.enable_new_executor()
config.set_optimization_level(3)
- config.delete_pass("matmul_add_act_fuse_pass")
+ # TODO(changdazhou): use a black list instead
+ if self._model_name == "PP-DocLayoutV3":
+ config.delete_pass("matmul_add_act_fuse_pass")
+ # ROCm does not support fused_conv2d_add_act kernel, delete the fuse passes
+ if paddle.is_compiled_with_rocm():
+ config.delete_pass("conv2d_add_act_fuse_pass")
+ config.delete_pass("conv2d_add_fuse_pass")
elif self._option.device_type == "npu":
config.enable_custom_device("npu", self._option.device_id)
if hasattr(config, "enable_new_ir"):
@@ -480,7 +486,9 @@ def _create(
if hasattr(config, "enable_new_executor"):
config.enable_new_executor()
config.set_optimization_level(3)
-
+ if paddle.is_compiled_with_rocm():
+ config.delete_pass("conv2d_add_act_fuse_pass")
+ config.delete_pass("conv2d_add_fuse_pass")
config.enable_memory_optim()
for del_p in self._option.delete_pass:
config.delete_pass(del_p)
@@ -488,6 +496,10 @@ def _create(
# Disable paddle inference logging
if not DEBUG:
config.disable_glog_info()
+ # ROCm does not support fused_conv2d_add_act kernel, delete the fuse passes
+ if paddle.is_compiled_with_rocm():
+ config.delete_pass("conv2d_add_act_fuse_pass")
+ config.delete_pass("conv2d_add_fuse_pass")
predictor = paddle.inference.create_predictor(config)
diff --git a/paddlex/inference/models/doc_vlm/modeling/paddleocr_vl/_paddleocr_vl.py b/paddlex/inference/models/doc_vlm/modeling/paddleocr_vl/_paddleocr_vl.py
index 93b61b6cc4..ab5a9cd87e 100644
--- a/paddlex/inference/models/doc_vlm/modeling/paddleocr_vl/_paddleocr_vl.py
+++ b/paddlex/inference/models/doc_vlm/modeling/paddleocr_vl/_paddleocr_vl.py
@@ -65,7 +65,9 @@ class PaddleOCRVLForConditionalGeneration(Ernie4_5PretrainedModel):
_tied_weights_keys = ["lm_head.weight"]
config_class = PaddleOCRVLConfig
_no_split_modules = ["Ernie4_5DecoderLayer", "SiglipEncoderLayer"]
-
+ # Keep visual encoder in fp32 for ROCm stability (MIOpen bf16 conv has bugs)
+ # This also improves precision for vision processing
+ _keep_in_fp32_modules = ["visual", "mlp_AR"]
base_model_prefix = ""
def __init__(self, config):
diff --git a/paddlex/inference/models/doc_vlm/predictor.py b/paddlex/inference/models/doc_vlm/predictor.py
index 9cd9341736..3f983a8d3a 100644
--- a/paddlex/inference/models/doc_vlm/predictor.py
+++ b/paddlex/inference/models/doc_vlm/predictor.py
@@ -167,10 +167,10 @@ def _build(self, **kwargs):
return model, processor
def _determine_batch_size(self):
- if self._model_name == "PaddleOCR-VL-0.9B":
+ if self._model_name in ("PaddleOCR-VL-0.9B", "PaddleOCR-VL-1.5-0.9B"):
batch_size = 1
if not self._use_local_model:
- batch_size = 4096
+ batch_size = 8192
logging.debug(
f"The batch size of {self._model_name} is determined to be {batch_size}."
)
@@ -415,118 +415,134 @@ def _genai_client_process(
max_pixels,
):
futures = []
- for item in data:
- image = item["image"]
- if isinstance(image, str):
- if image.startswith("http://") or image.startswith("https://"):
- image_url = image
- else:
+ if self._genai_client.backend == "llama-cpp-server":
+ image_format = "PNG"
+ else:
+ image_format = "JPEG"
+ try:
+ for item in data:
+ image = item["image"]
+ if isinstance(image, str):
+ if image.startswith("http://") or image.startswith("https://"):
+ image_url = image
+ else:
+ from PIL import Image
+
+ with Image.open(image) as img:
+ img = img.convert("RGB")
+ with io.BytesIO() as buf:
+ img.save(buf, format=image_format)
+ image_url = (
+ f"data:image/{image_format.lower()};base64,"
+ + base64.b64encode(buf.getvalue()).decode("ascii")
+ )
+ elif isinstance(image, np.ndarray):
+ import cv2
from PIL import Image
- with Image.open(image) as img:
- img = img.convert("RGB")
- with io.BytesIO() as buf:
- img.save(buf, format="JPEG")
- image_url = "data:image/jpeg;base64," + base64.b64encode(
- buf.getvalue()
- ).decode("ascii")
- elif isinstance(image, np.ndarray):
- import cv2
- from PIL import Image
-
- image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
- img = Image.fromarray(image)
- with io.BytesIO() as buf:
- img.save(buf, format="JPEG")
- image_url = "data:image/jpeg;base64," + base64.b64encode(
- buf.getvalue()
- ).decode("ascii")
- else:
- raise TypeError(f"Not supported image type: {type(image)}")
-
- if self._genai_client.backend == "fastdeploy-server":
- kwargs = {
- "temperature": 1 if temperature is None else temperature,
- "top_p": 0 if top_p is None else top_p,
- }
- else:
- kwargs = {
- "temperature": 0 if temperature is None else temperature,
- }
- if top_p is not None:
- kwargs["top_p"] = top_p
-
- if self._genai_client.backend == "mlx-vlm-server":
- max_tokens_name = "max_tokens"
- else:
- max_tokens_name = "max_completion_tokens"
-
- if max_new_tokens is not None:
- kwargs[max_tokens_name] = max_new_tokens
- elif self.model_name in self.model_group["PaddleOCR-VL"]:
- kwargs[max_tokens_name] = 8192
-
- kwargs["extra_body"] = {}
- if skip_special_tokens is not None:
- if self._genai_client.backend in (
- "fastdeploy-server",
- "vllm-server",
- "sglang-server",
- "mlx-vlm-server",
- ):
- kwargs["extra_body"]["skip_special_tokens"] = skip_special_tokens
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
+ img = Image.fromarray(image)
+ with io.BytesIO() as buf:
+ img.save(buf, format=image_format)
+ image_url = (
+ f"data:image/{image_format.lower()};base64,"
+ + base64.b64encode(buf.getvalue()).decode("ascii")
+ )
else:
- raise ValueError("Not supported")
+ raise TypeError(f"Not supported image type: {type(image)}")
- if repetition_penalty is not None:
- kwargs["extra_body"]["repetition_penalty"] = repetition_penalty
-
- if min_pixels is not None:
- if self._genai_client.backend == "vllm-server":
- kwargs["extra_body"]["mm_processor_kwargs"] = kwargs[
- "extra_body"
- ].get("mm_processor_kwargs", {})
- kwargs["extra_body"]["mm_processor_kwargs"][
- "min_pixels"
- ] = min_pixels
+ if self._genai_client.backend == "fastdeploy-server":
+ kwargs = {
+ "temperature": 1 if temperature is None else temperature,
+ "top_p": 0 if top_p is None else top_p,
+ }
else:
- warnings.warn(
- f"{repr(self._genai_client.backend)} does not support `min_pixels`."
- )
+ kwargs = {
+ "temperature": 0 if temperature is None else temperature,
+ }
+ if top_p is not None:
+ kwargs["top_p"] = top_p
- if max_pixels is not None:
- if self._genai_client.backend == "vllm-server":
- kwargs["extra_body"]["mm_processor_kwargs"] = kwargs[
- "extra_body"
- ].get("mm_processor_kwargs", {})
- kwargs["extra_body"]["mm_processor_kwargs"][
- "max_pixels"
- ] = max_pixels
+ if self._genai_client.backend in ["mlx-vlm-server", "llama-cpp-server"]:
+ max_tokens_name = "max_tokens"
else:
- warnings.warn(
- f"{repr(self._genai_client.backend)} does not support `max_pixels`."
- )
+ max_tokens_name = "max_completion_tokens"
+
+ if max_new_tokens is not None:
+ kwargs[max_tokens_name] = max_new_tokens
+ elif self.model_name in self.model_group["PaddleOCR-VL"]:
+ kwargs[max_tokens_name] = 8192
+
+ kwargs["extra_body"] = {}
+ if skip_special_tokens is not None:
+ if self._genai_client.backend in (
+ "fastdeploy-server",
+ "vllm-server",
+ "sglang-server",
+ "mlx-vlm-server",
+ "llama-cpp-server",
+ ):
+ kwargs["extra_body"][
+ "skip_special_tokens"
+ ] = skip_special_tokens
+ else:
+ raise ValueError("Not supported")
+
+ if repetition_penalty is not None:
+ kwargs["extra_body"]["repetition_penalty"] = repetition_penalty
- future = self._genai_client.create_chat_completion(
- [
- {
- "role": "user",
- "content": [
- {"type": "image_url", "image_url": {"url": image_url}},
- {"type": "text", "text": item["query"]},
- ],
- }
- ],
- return_future=True,
- timeout=600,
- **kwargs,
- )
+ if min_pixels is not None:
+ if self._genai_client.backend == "vllm-server":
+ kwargs["extra_body"]["mm_processor_kwargs"] = kwargs[
+ "extra_body"
+ ].get("mm_processor_kwargs", {})
+ kwargs["extra_body"]["mm_processor_kwargs"][
+ "min_pixels"
+ ] = min_pixels
+ else:
+ warnings.warn(
+ f"{repr(self._genai_client.backend)} does not support `min_pixels`."
+ )
+
+ if max_pixels is not None:
+ if self._genai_client.backend == "vllm-server":
+ kwargs["extra_body"]["mm_processor_kwargs"] = kwargs[
+ "extra_body"
+ ].get("mm_processor_kwargs", {})
+ kwargs["extra_body"]["mm_processor_kwargs"][
+ "max_pixels"
+ ] = max_pixels
+ else:
+ warnings.warn(
+ f"{repr(self._genai_client.backend)} does not support `max_pixels`."
+ )
+
+ future = self._genai_client.create_chat_completion(
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image_url", "image_url": {"url": image_url}},
+ {"type": "text", "text": item["query"]},
+ ],
+ }
+ ],
+ return_future=True,
+ timeout=600,
+ **kwargs,
+ )
- futures.append(future)
+ futures.append(future)
- results = []
- for future in futures:
- result = future.result()
- results.append(result.choices[0].message.content)
+ results = []
+ for future in futures:
+ result = future.result()
+ results.append(result.choices[0].message.content)
- return results
+ return results
+ except Exception:
+ # Cancel all pending futures to avoid wasting resources
+ for future in futures:
+ if not future.done():
+ future.cancel()
+ raise
diff --git a/paddlex/inference/models/layout_analysis/processors.py b/paddlex/inference/models/layout_analysis/processors.py
index d1672a2000..b7ebaf0992 100644
--- a/paddlex/inference/models/layout_analysis/processors.py
+++ b/paddlex/inference/models/layout_analysis/processors.py
@@ -595,10 +595,15 @@ def filter_boxes(
continue
box_area_i = calculate_bbox_area(boxes[i]["coordinate"])
box_area_j = calculate_bbox_area(boxes[j]["coordinate"])
- if (
- boxes[i]["label"] == "image" or boxes[j]["label"] == "image"
- ) and boxes[i]["label"] != boxes[j]["label"]:
- continue
+ labels = {boxes[i]["label"], boxes[j]["label"]}
+ if labels & {"image", "table", "seal", "chart"} and len(labels) > 1:
+ if "table" not in labels or labels <= {
+ "table",
+ "image",
+ "seal",
+ "chart",
+ }:
+ continue
if box_area_i >= box_area_j:
dropped_indexes.add(j)
else:
diff --git a/paddlex/inference/pipelines/components/retriever/base.py b/paddlex/inference/pipelines/components/retriever/base.py
index a348836836..b4f067951e 100644
--- a/paddlex/inference/pipelines/components/retriever/base.py
+++ b/paddlex/inference/pipelines/components/retriever/base.py
@@ -21,13 +21,23 @@
from .....utils.deps import class_requires_deps, is_dep_available
from .....utils.subclass_register import AutoRegisterABCMetaClass
-if is_dep_available("langchain"):
- from langchain.docstore.document import Document
- from langchain.text_splitter import RecursiveCharacterTextSplitter
+
if is_dep_available("langchain-community"):
from langchain_community import vectorstores
from langchain_community.vectorstores import FAISS
+# Document import capability
+try:
+ from langchain_core.documents import Document
+except ImportError:
+ from langchain.docstore.document import Document
+
+# Text splitter compatibility
+try:
+ from langchain_text_splitters import RecursiveCharacterTextSplitter
+except ImportError:
+ from langchain.text_splitter import RecursiveCharacterTextSplitter
+
@class_requires_deps("langchain", "langchain-community")
class BaseRetriever(ABC, metaclass=AutoRegisterABCMetaClass):
diff --git a/paddlex/inference/pipelines/paddleocr_vl/pipeline.py b/paddlex/inference/pipelines/paddleocr_vl/pipeline.py
index ee1994d83d..5a48667437 100644
--- a/paddlex/inference/pipelines/paddleocr_vl/pipeline.py
+++ b/paddlex/inference/pipelines/paddleocr_vl/pipeline.py
@@ -272,7 +272,7 @@ def get_layout_parsing_results(
id2pixel_key_map = {}
image_path_to_obj_map = {}
vis_image_labels = IMAGE_LABELS + ["seal"]
- image_labels = [] if use_ocr_for_image_block else IMAGE_LABELS
+ image_labels = [] if use_ocr_for_image_block else IMAGE_LABELS.copy()
if not use_chart_recognition:
image_labels += ["chart"]
vis_image_labels += ["chart"]
diff --git a/paddlex/inference/pipelines/paddleocr_vl/result.py b/paddlex/inference/pipelines/paddleocr_vl/result.py
index 963f9db79f..dc7dc92c98 100644
--- a/paddlex/inference/pipelines/paddleocr_vl/result.py
+++ b/paddlex/inference/pipelines/paddleocr_vl/result.py
@@ -268,7 +268,7 @@ def __init__(self, data) -> None:
"markdown_ignore_labels", []
)
self.skip_order_labels = [
- label for label in SKIP_ORDER_LABELS + markdown_ignore_labels
+ label for label in SKIP_ORDER_LABELS.copy() + markdown_ignore_labels
]
def _to_img(self) -> dict[str, np.ndarray]:
@@ -468,7 +468,7 @@ def _to_json(self, *args, **kwargs) -> dict[str, str]:
original_image_width=original_image_width,
show_ocr_content=True,
),
- remove_symbol=use_seal_recognition,
+ remove_symbol=not use_seal_recognition,
)
if self["model_settings"].get("use_chart_recognition", False):
diff --git a/paddlex/inference/pipelines/paddleocr_vl/uilts.py b/paddlex/inference/pipelines/paddleocr_vl/uilts.py
index 8a4009a473..c753ec9d32 100644
--- a/paddlex/inference/pipelines/paddleocr_vl/uilts.py
+++ b/paddlex/inference/pipelines/paddleocr_vl/uilts.py
@@ -123,13 +123,15 @@ def filter_overlap_boxes(
continue
box_area_i = calculate_bbox_area(boxes[i]["coordinate"])
box_area_j = calculate_bbox_area(boxes[j]["coordinate"])
- if {boxes[i]["label"], boxes[j]["label"]} & {
- "image",
- "table",
- "seal",
- "chart",
- } and boxes[i]["label"] != boxes[j]["label"]:
- continue
+ labels = {boxes[i]["label"], boxes[j]["label"]}
+ if labels & {"image", "table", "seal", "chart"} and len(labels) > 1:
+ if "table" not in labels or labels <= {
+ "table",
+ "image",
+ "seal",
+ "chart",
+ }:
+ continue
if box_area_i >= box_area_j:
dropped_indexes.add(j)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/common.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/common.py
index 82b8bf580a..87347fb034 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/common.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/common.py
@@ -50,6 +50,7 @@ def postprocess_image(
*,
file_storage: Optional[Storage] = None,
return_url: bool = False,
+ url_expires_in: int = -1,
max_img_size: Optional[Tuple[int, int]] = None,
) -> str:
if return_url:
@@ -75,7 +76,7 @@ def postprocess_image(
file_storage.set(key, img_bytes)
if return_url:
assert isinstance(file_storage, SupportsGetURL)
- return file_storage.get_url(key)
+ return file_storage.get_url(key, expires_in=url_expires_in)
return serving_utils.base64_encode(img_bytes)
@@ -85,6 +86,7 @@ def postprocess_images(
filename_template: str = "{key}.jpg",
file_storage: Optional[Storage] = None,
return_urls: bool = False,
+ url_expires_in: int = -1,
max_img_size: Optional[Tuple[int, int]] = None,
) -> Dict[str, str]:
output_images: Dict[str, str] = {}
@@ -99,6 +101,7 @@ def postprocess_images(
filename=filename_template.format(key=key),
file_storage=file_storage,
return_url=return_urls,
+ url_expires_in=url_expires_in,
max_img_size=max_img_size,
)
return output_images
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/ocr.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/ocr.py
index 1d46eadb20..73473800d2 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/ocr.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/_common/ocr.py
@@ -31,6 +31,7 @@
DEFAULT_MAX_NUM_INPUT_IMGS: Final[int] = 10
DEFAULT_MAX_OUTPUT_IMG_SIZE: Final[Tuple[int, int]] = (2000, 2000)
+DEFAULT_URL_EXPIRES_IN: Final[int] = -1
def update_app_context(app_context: AppContext) -> None:
@@ -49,6 +50,9 @@ def update_app_context(app_context: AppContext) -> None:
raise TypeError(
f"`{type(file_storage).__name__}` does not support getting URLs."
)
+ app_context.extra["url_expires_in"] = extra_cfg.get(
+ "url_expires_in", DEFAULT_URL_EXPIRES_IN
+ )
app_context.extra["max_num_input_imgs"] = extra_cfg.get(
"max_num_input_imgs", DEFAULT_MAX_NUM_INPUT_IMGS
)
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/doc_preprocessor.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/doc_preprocessor.py
index e9e837a50f..2bd38780cb 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/doc_preprocessor.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/doc_preprocessor.py
@@ -80,6 +80,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/formula_recognition.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/formula_recognition.py
index 786c426d91..8cc3343641 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/formula_recognition.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/formula_recognition.py
@@ -75,6 +75,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing.py
index a778632cff..e35633e969 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing.py
@@ -91,7 +91,7 @@ async def _infer(
log_id,
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
- return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/ocr.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/ocr.py
index 4020a4f48b..72e3382ed1 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/ocr.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/ocr.py
@@ -81,6 +81,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/paddleocr_vl.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/paddleocr_vl.py
index 1eaa219d86..f2f0a46450 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/paddleocr_vl.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/paddleocr_vl.py
@@ -111,6 +111,7 @@ async def _infer(
filename_template=f"markdown_{i}/{{key}}",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
if visualize_enabled:
@@ -125,6 +126,7 @@ async def _infer(
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv3_doc.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv3_doc.py
index 8e74699f14..4e449bca0e 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv3_doc.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv3_doc.py
@@ -92,6 +92,7 @@ async def _analyze_images(
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv4_doc.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv4_doc.py
index ced0e6bb88..071a6a2f3d 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv4_doc.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_chatocrv4_doc.py
@@ -93,6 +93,7 @@ async def _analyze_images(
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_doctranslation.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_doctranslation.py
index f4a6c88a13..232dae19aa 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_doctranslation.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_doctranslation.py
@@ -100,6 +100,7 @@ async def _analyze_images(
filename_template=f"markdown_{i}/{{key}}",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
md_flags = md_data["page_continuation_flags"]
@@ -115,6 +116,7 @@ async def _analyze_images(
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_structurev3.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_structurev3.py
index 79e1e17ee6..b68ab3369a 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_structurev3.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_structurev3.py
@@ -103,6 +103,7 @@ async def _infer(
filename_template=f"markdown_{i}/{{key}}",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
md_flags = md_data["page_continuation_flags"]
@@ -118,6 +119,7 @@ async def _infer(
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/seal_recognition.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/seal_recognition.py
index 012f94abb8..1c85b56d13 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/seal_recognition.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/seal_recognition.py
@@ -81,6 +81,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition.py
index eecd45be99..9ca46ade4c 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition.py
@@ -79,6 +79,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition_v2.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition_v2.py
index 288a415fca..8adef8afd7 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition_v2.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/table_recognition_v2.py
@@ -84,6 +84,7 @@ async def _infer(request: InferRequest) -> AIStudioResultResponse[InferResult]:
filename_template=f"{{key}}_{i}.jpg",
file_storage=ctx.extra["file_storage"],
return_urls=ctx.extra["return_img_urls"],
+ url_expires_in=ctx.extra["url_expires_in"],
max_img_size=ctx.extra["max_output_img_size"],
)
else:
diff --git a/paddlex/inference/serving/infra/storage.py b/paddlex/inference/serving/infra/storage.py
index 7a0cbbf929..ddda1b3838 100644
--- a/paddlex/inference/serving/infra/storage.py
+++ b/paddlex/inference/serving/infra/storage.py
@@ -65,7 +65,7 @@ class BOSConfig(BaseModel):
@runtime_checkable
class SupportsGetURL(Protocol):
- def get_url(self, key: str) -> str: ...
+ def get_url(self, key: str, expires_in: int = -1) -> str: ...
class Storage(metaclass=abc.ABCMeta):
@@ -156,10 +156,12 @@ def delete(self, key: str) -> None:
key = self._get_full_key(key)
self._client.delete_object(bucket_name=self._bucket_name, key=key)
- def get_url(self, key: str) -> str:
+ def get_url(self, key: str, expires_in: int = -1) -> str:
key = self._get_full_key(key)
return self._client.generate_pre_signed_url(
- self._bucket_name, key, expiration_in_seconds=-1
+ self._bucket_name,
+ key,
+ expiration_in_seconds=expires_in,
).decode("ascii")
def _get_full_key(self, key: str) -> str:
diff --git a/paddlex/inference/serving/infra/utils.py b/paddlex/inference/serving/infra/utils.py
index b6b0211f98..7c67567957 100644
--- a/paddlex/inference/serving/infra/utils.py
+++ b/paddlex/inference/serving/infra/utils.py
@@ -30,6 +30,7 @@
from typing_extensions import Literal, ParamSpec, TypeAlias, assert_never
from ....utils.deps import function_requires_deps, is_dep_available
+from ....utils.flags import PDF_RENDER_SCALE
from ...utils.pdfium_lock import pdfium_lock
from .models import ImageInfo, PDFInfo, PDFPageInfo
@@ -191,8 +192,7 @@ def read_pdf(
if max_num_imgs is not None and len(images) >= max_num_imgs:
page.close()
break
- # TODO: Do not always use zoom=2.0
- zoom = 2.0
+ zoom = PDF_RENDER_SCALE
deg = 0
image = page.render(scale=zoom, rotation=deg).to_numpy()
images.append(image)
diff --git a/paddlex/utils/custom_device_list.py b/paddlex/utils/custom_device_list.py
index ec4a85495c..d48ea12b71 100755
--- a/paddlex/utils/custom_device_list.py
+++ b/paddlex/utils/custom_device_list.py
@@ -418,6 +418,7 @@
"PP-OCRv4_mobile_rec",
"PP-OCRv4_server_rec",
"PP-DocLayoutV2",
+ "PP-DocLayoutV3",
"PP-ShiTuV2_rec",
"PP-ShiTuV2_det",
"PP-OCRv5_mobile_det",
diff --git a/paddlex/utils/flags.py b/paddlex/utils/flags.py
index 1fcf547335..726d3603fd 100644
--- a/paddlex/utils/flags.py
+++ b/paddlex/utils/flags.py
@@ -70,7 +70,9 @@ def get_flag_from_env_var(name, default, format_func=str):
"PADDLE_PDX_DISABLE_MODEL_SOURCE_CHECK", False
)
-HUGGING_FACE_ENDPOINT = os.environ.get("PADDLE_PDX_HUGGING_FACE_ENDPOINT", "https://huggingface.co")
+HUGGING_FACE_ENDPOINT = os.environ.get(
+ "PADDLE_PDX_HUGGING_FACE_ENDPOINT", "https://huggingface.co"
+)
# Inference Benchmark
INFER_BENCHMARK = get_flag_from_env_var("PADDLE_PDX_INFER_BENCHMARK", False)
@@ -87,3 +89,5 @@ def get_flag_from_env_var(name, default, format_func=str):
INFER_BENCHMARK_USE_CACHE_FOR_READ = get_flag_from_env_var(
"PADDLE_PDX_INFER_BENCHMARK_USE_CACHE_FOR_READ", False
)
+
+PDF_RENDER_SCALE = get_flag_from_env_var("PADDLE_PDX_PDF_RENDER_SCALE", 2.0, float)
diff --git a/setup.py b/setup.py
index c2401ff4c1..a3a43d9f88 100644
--- a/setup.py
+++ b/setup.py
@@ -40,10 +40,11 @@
"jieba": "",
"Jinja2": "",
"joblib": "",
- "langchain": ">= 0.2, < 1.0",
- "langchain-community": ">= 0.2, < 1.0",
+ "langchain": ">= 0.2",
+ "langchain-community": ">= 0.2",
"langchain-core": "",
- "langchain-openai": ">= 0.1, < 1.0",
+ "langchain-openai": ">= 0.1",
+ "langchain_text_splitters": "",
"lxml": "",
"matplotlib": "",
"modelscope": ">=1.28.0",
@@ -114,7 +115,6 @@
# Currently `pypdfium2` is required by the image batch sampler
"pypdfium2",
"scikit-image",
- "scipy",
],
"multimodal": [
"einops",
@@ -229,7 +229,7 @@
"genai-vllm-server": [
"einops",
"torch == 2.8.0",
- "transformers",
+ "transformers < 5.0.0",
"uvloop",
"vllm == 0.10.2",
],