Machine Learning > Sesión 03

- Construir algoritmos que permitan hacer separación en conjuntos sin necesidad de suministrar datos de categorización.

La principal diferencia entre algoritmos supervisados y no supervisados en Machine Learning radica en la presencia o ausencia de etiquetas en los datos:
Algoritmos Supervisados:
- Utilizan datos etiquetados para entrenar un modelo.
- El objetivo es predecir o clasificar datos nuevos en función de patrones aprendidos de los datos de entrenamiento.
- Ejemplos incluyen regresión y clasificación, donde se conocen las etiquetas de los datos de entrenamiento.
Algoritmos No Supervisados:
- No requieren etiquetas en los datos de entrenamiento.
- El objetivo principal es encontrar patrones, estructuras o agrupaciones en los datos sin guía previa.
- Ejemplos incluyen el clustering (agrupamiento), donde se identifican grupos naturales en los datos, y la reducción de dimensionalidad, que reduce la complejidad de los datos sin necesidad de etiquetas.
En resumen, los algoritmos supervisados se utilizan para tareas de predicción y clasificación con datos etiquetados, mientras que los algoritmos no supervisados se utilizan para explorar patrones desconocidos o estructuras en los datos sin necesidad de etiquetas.
Un algoritmo no supervisado es útil en varias situaciones en el campo del Machine Learning y el análisis de datos:
-
Agrupamiento (Clustering): Permite identificar grupos naturales dentro de los datos, lo que es útil para segmentar clientes, usuarios, productos, o cualquier otro tipo de entidad en categorías significativas.
-
Reducción de Dimensionalidad: Ayuda a reducir la complejidad de los datos al proyectarlos en un espacio de menor dimensión. Esto es beneficioso para la visualización de datos, la eliminación de características irrelevantes y la mejora del rendimiento de los modelos.
-
Detección de Anomalías: Puede utilizarse para identificar puntos de datos anómalos o valores atípicos en un conjunto de datos, lo que es fundamental en la detección de fraudes, mantenimiento predictivo y seguridad.
-
Generación de Características: Algunos algoritmos no supervisados, como el Análisis de Componentes Principales (PCA) y las redes generativas, pueden utilizarse para crear nuevas características que resuman la información importante en los datos.
-
Preprocesamiento de Datos: Puede utilizarse como parte del preprocesamiento de datos para limpiar, normalizar y transformar datos antes de utilizarlos en modelos supervisados.
En resumen, los algoritmos no supervisados son herramientas valiosas en el análisis exploratorio de datos, la segmentación de datos y la reducción de la complejidad de los datos, lo que a menudo conduce a una mejor comprensión y toma de decisiones en una variedad de aplicaciones.

K-Means es un algoritmo de clustering utilizado en Machine Learning y análisis de datos. Su funcionamiento se resume de la siguiente manera:
-
Inicialización: Selecciona aleatoriamente K centroides iniciales, donde K es el número de clusters que deseas encontrar.
-
Asignación: Asigna cada punto de datos al centroide más cercano en función de una métrica de distancia, generalmente la distancia euclidiana.
-
Actualización: Recalcula los centroides de cada cluster como el promedio de los puntos asignados a ese cluster.
-
Repetición: Repite los pasos 2 y 3 hasta que los centroides converjan o se alcance un número máximo de iteraciones.
-
Resultados: El algoritmo devuelve los centroides finales y la asignación de cada punto a un cluster.
El resultado es un conjunto de clusters, donde los puntos dentro de un cluster son similares entre sí en términos de distancia. K-Means se utiliza para segmentar datos en grupos cohesivos y se aplica en una amplia variedad de aplicaciones, como segmentación de clientes, compresión de imágenes y más.

El Análisis de Grupos de K-Means utilizando gráficas de densidad implica visualizar la distribución de los datos en cada cluster. Aquí tienes los pasos básicos:
-
Ejecuta K-Means: Aplica el algoritmo K-Means para agrupar tus datos en clusters.
-
Calcula la Densidad: Para cada cluster, calcula la densidad de puntos en función de la distancia a su centroide. Puedes usar estimaciones de densidad de kernel, histogramas o cualquier otra técnica adecuada.
-
Visualiza las Gráficas de Densidad: Crea gráficas de densidad separadas para cada cluster. Estas gráficas mostrarán cómo se distribuyen los puntos dentro de cada grupo en términos de densidad.
-
Interpreta las Gráficas: Observa las gráficas de densidad para identificar patrones en la distribución de los datos. Esto te ayudará a comprender la cohesión y la separación entre los clusters.
-
Toma Decisiones: Basándote en la interpretación de las gráficas de densidad, puedes tomar decisiones sobre la validez de tus clusters y ajustar el número de clusters si es necesario.
Este enfoque te permite explorar visualmente cómo los datos se agrupan en clusters y cómo se distribuyen dentro de cada cluster en términos de densidad, lo que puede proporcionar información valiosa sobre la calidad de tus resultados de K-Means.
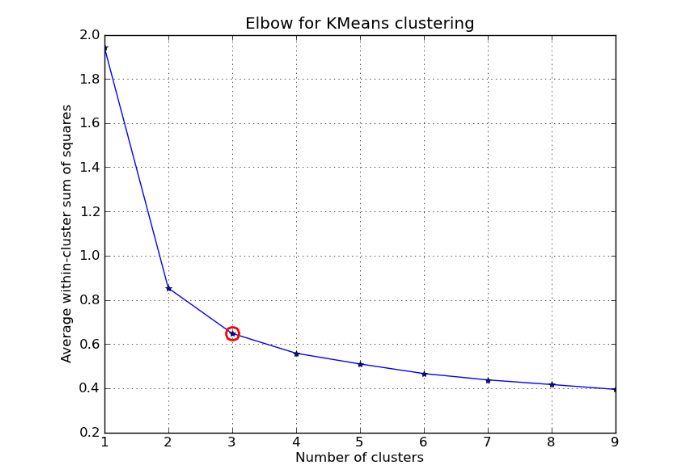
El método del codo es una técnica utilizada para determinar el número óptimo de clusters (K) en un algoritmo de K-Means. Aquí está la explicación breve del método:
-
Ejecuta K-Means: Aplica el algoritmo K-Means a tus datos para diferentes valores de K, comenzando con K = 1 y aumentando gradualmente.
-
Calcula la Suma de Cuadrados Intra-cluster (WCSS): Para cada valor de K, calcula la suma de las distancias al cuadrado entre cada punto de datos y el centroide de su cluster asignado. El WCSS mide la dispersión de los puntos dentro de cada cluster.
-
Dibuja el Gráfico del WCSS: Representa el valor del WCSS en función de K en un gráfico. Verás que a medida que aumentas K, el WCSS tiende a disminuir porque cada cluster es más pequeño y los puntos están más cerca de sus centroides.
-
Identifica el Codo: Examina el gráfico del WCSS y busca un punto donde la disminución en el WCSS se desacelera significativamente, creando una curva que se asemeja a un "codo". Este punto es a menudo considerado como el número óptimo de clusters.
El método del codo te ayuda a seleccionar un valor de K que equilibra la cohesión dentro de los clusters con la separación entre los clusters. Sin embargo, ten en cuenta que en algunos casos, el gráfico del WCSS puede no tener un codo claro, y la elección de K puede requerir un juicio adicional.

Puedes construir un sistema de recomendación utilizando K-Means de la siguiente manera:
-
Preparación de datos: Reúne datos relevantes para tu sistema de recomendación. Por ejemplo, si estás construyendo un sistema de recomendación de películas, necesitarás datos de usuarios y películas, así como información sobre las interacciones entre usuarios y películas, como calificaciones o visualizaciones.
-
Representación de datos: Convierte tus datos en una matriz de características donde cada fila representa un usuario y cada columna representa una película. Las celdas de la matriz pueden contener información como calificaciones, puntajes de similitud, o cualquier medida relevante de interacción entre usuarios y películas.
-
Clustering con K-Means: Aplica el algoritmo K-Means a tu matriz de datos. El objetivo aquí es agrupar usuarios o elementos similares en clusters. Puedes optar por agrupar usuarios similares o películas similares, dependiendo de tu enfoque (filtrado colaborativo basado en usuario o basado en ítems).
-
Asignación de clusters: Asigna cada usuario o película a uno de los clusters generados por K-Means. Esto determinará a qué grupo pertenece cada usuario o película en función de sus similitudes con otros.
-
Generación de recomendaciones: Para hacer una recomendación, selecciona un usuario o película de interés y encuentra otros usuarios o películas que pertenezcan al mismo cluster. Las recomendaciones se pueden generar a partir de los elementos en ese cluster que el usuario aún no ha interactuado o calificado.
-
Evaluación del sistema: Evalúa la calidad de las recomendaciones utilizando métricas como la precisión, la cobertura y la tasa de aciertos. Puedes usar técnicas de validación cruzada para evaluar el rendimiento de tu sistema.
-
Optimización de K-Means: Experimenta con diferentes valores de K en el algoritmo K-Means para encontrar el número óptimo de clusters que produzca las mejores recomendaciones.
-
Implementación y despliegue: Implementa tu sistema de recomendación en una aplicación web o plataforma según tus necesidades y despliégalo para que los usuarios puedan interactuar con él.
Un sistema de recomendación basado en K-Means puede ser efectivo para agrupar usuarios o elementos similares y proporcionar recomendaciones personalizadas. Sin embargo, también hay otros enfoques, como el filtrado colaborativo y las técnicas de factorización matricial, que pueden utilizarse en sistemas de recomendación más avanzados. La elección del enfoque dependerá de tus datos y objetivos específicos.