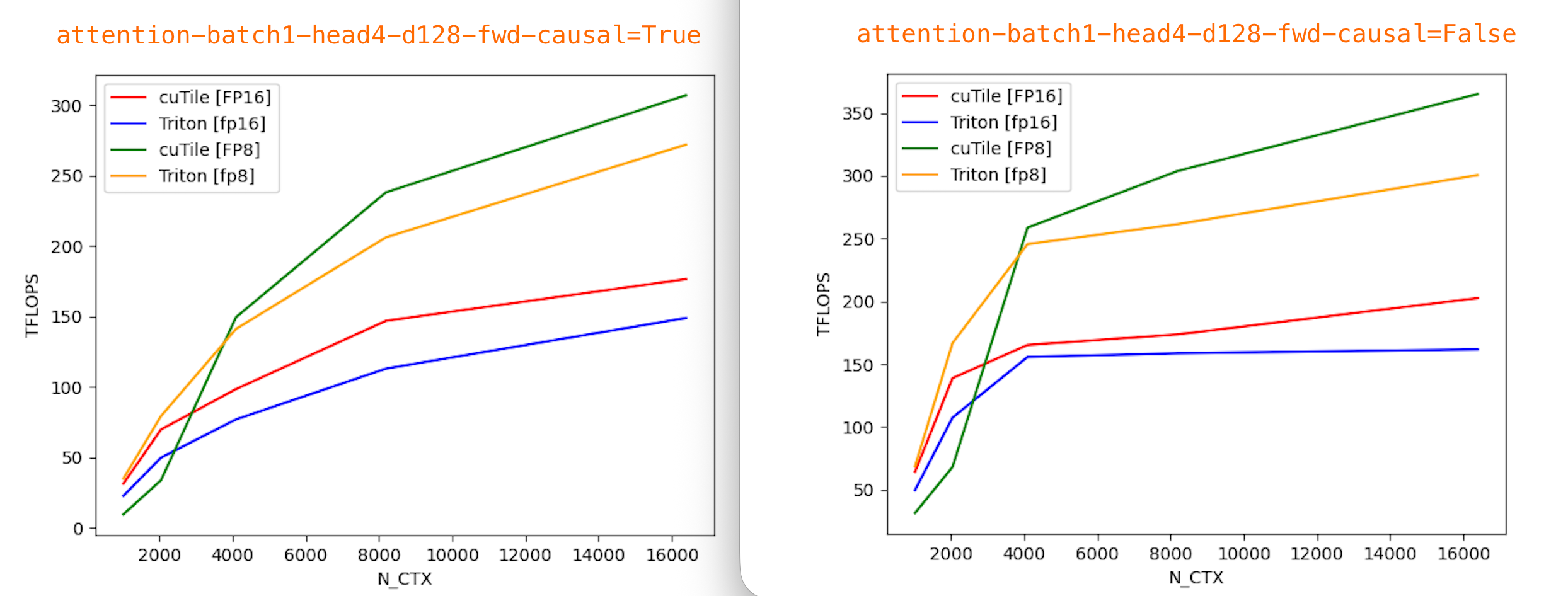
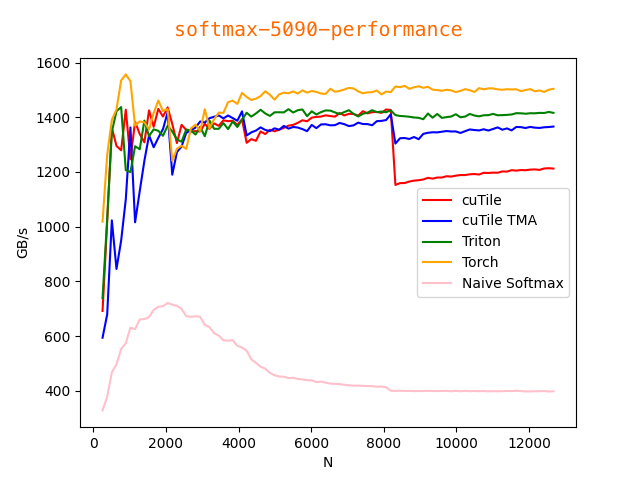
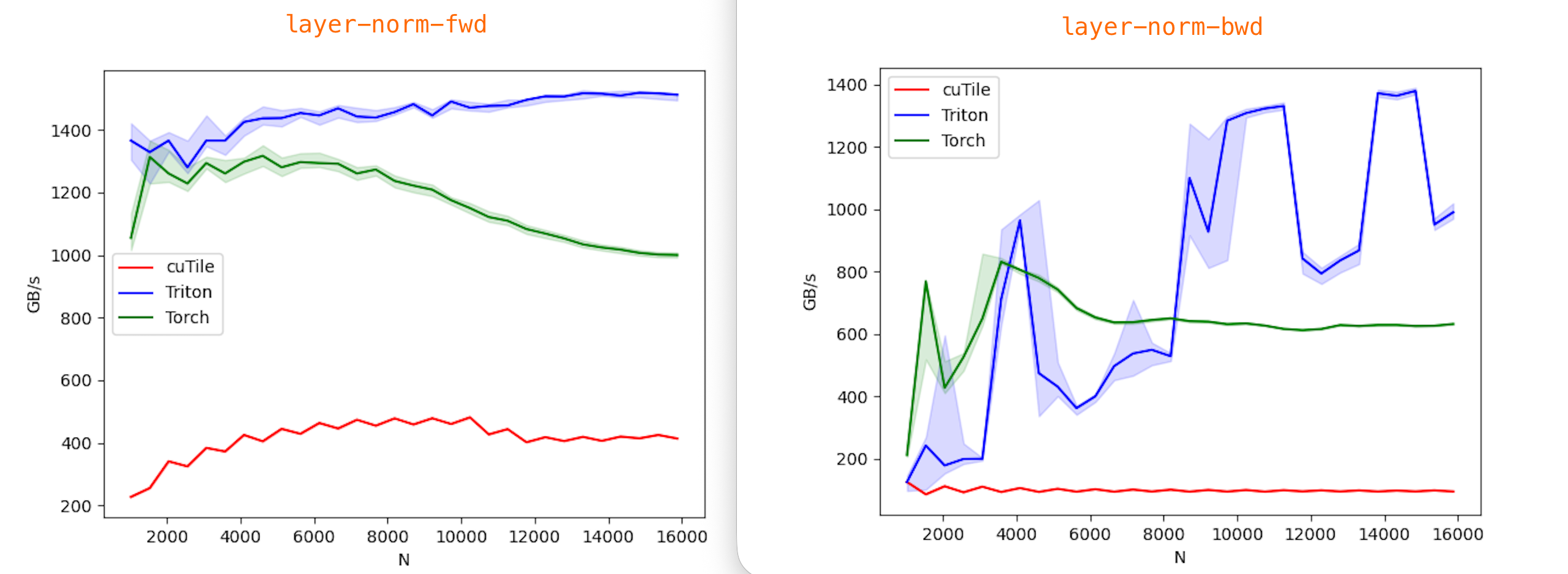
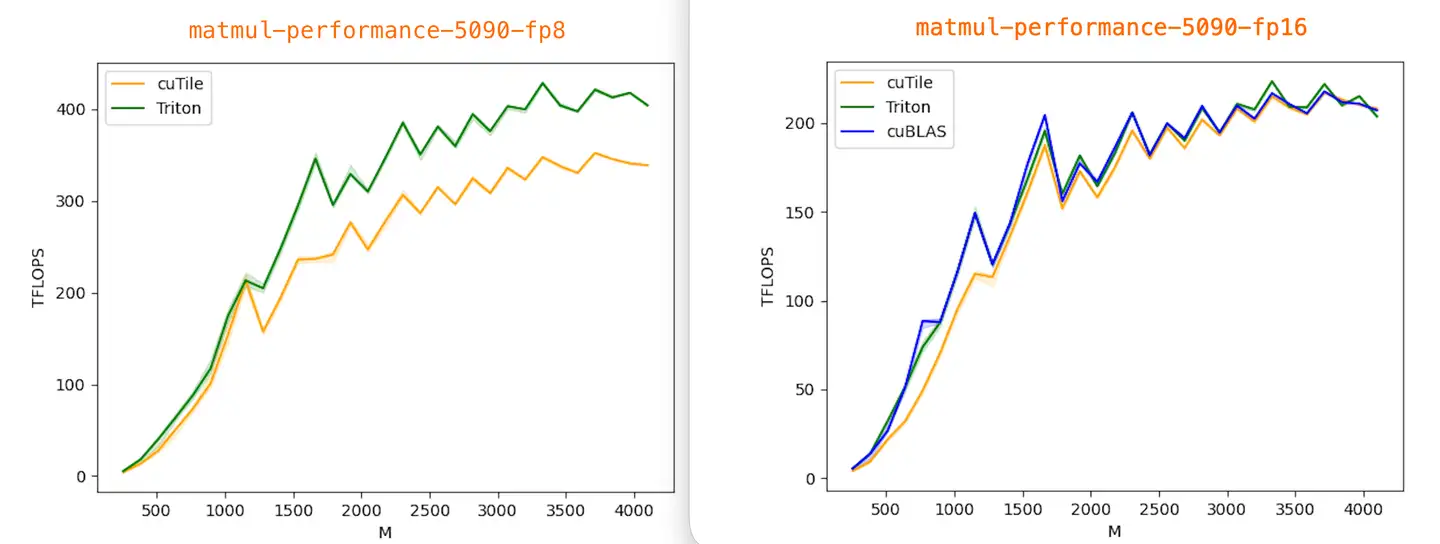
All benchmarks were run with Torch 2.9.1, Triton 3.5.1, cuTile (cuda-tile) 1.0.0, and tileiras, using CUDA compilation tools 13.1 (V13.1.80).
Currently, I only have results from an RTX 5090 (sm_120), data in benchmark/5090. Contributions from Blackwell B200 (sm_100) users are very welcome!
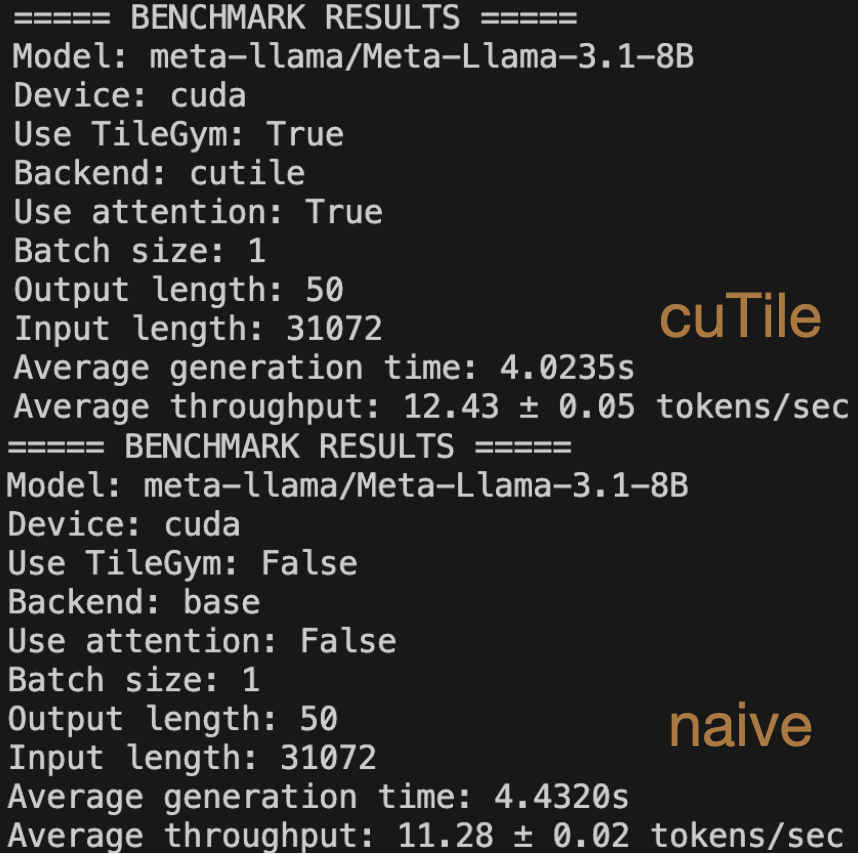
use NVIDIA/TileGym/tree/main/modeling/transformers and profile data in profile-data repository