-
-
数据审核就是检查数据中是否有错误。从完整性和准确性两方面入手,完整性审核主要是检查应调查的单位或个体是否有遗漏,准确性审核主要是检查数据是否有错误,是否存在异常值等。
-
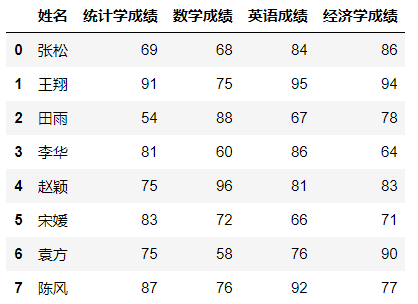
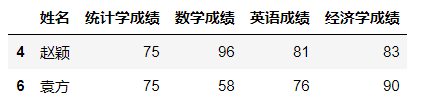
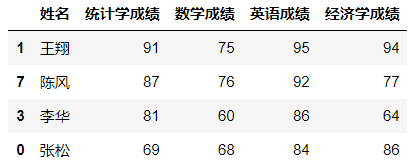
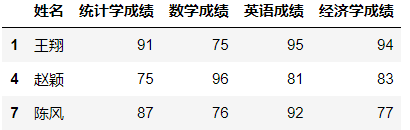
数据筛选(data filter)是根据需要找出符合特定条件的某类数据。如在以下数据中找出统计学成绩等于75分的学生,英语成绩最高的前三名学生,四门课程成绩都大于70分的学生。
使用pandas进行求解:
df = pd.read_excel('data/3.数据的图表展示/例题/例3.1.xlsx') #导入数据 df[df['统计学成绩'] == 75]
df.sort_values(by='英语成绩', ascending=False).iloc[:4, :]
df[(df['统计学成绩'] > 70) & (df['数学成绩'] > 70) & (df['英语成绩'] > 70) & (df['经济学成绩'] > 70)]
-
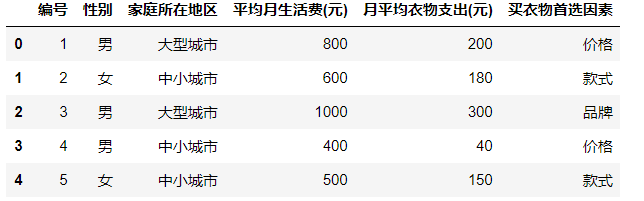
df = pd.read_excel('data/3.数据的图表展示/例题/例3.2.xlsx') #导入数据 df.head()
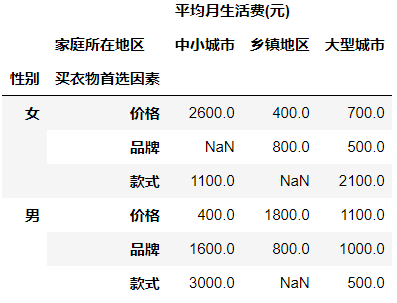
pd.pivot_table(df,values=['平均月生活费(元)'],columns='家庭所在地区',index=['性别','买衣物首选因素'],aggfunc=np.sum)
-
-
-
-
频数与频数分布
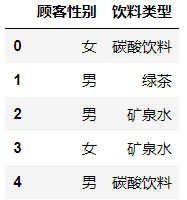
df = pd.read_excel('data/3.数据的图表展示/例题/例3.3.xlsx') #导入数据 df.head()
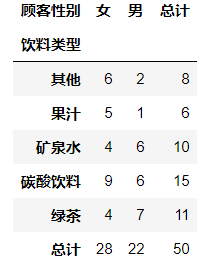
pd.crosstab(df['饮料类型'],df['顾客性别'],margins=True,margins_name='总计')
-
分类数据的图示
-
条形图
条形图(bar chart)是用宽度相同的条形的高度或长短来表示数据多少的图形。条形图可以横置或纵置,纵置时也称为柱形图。
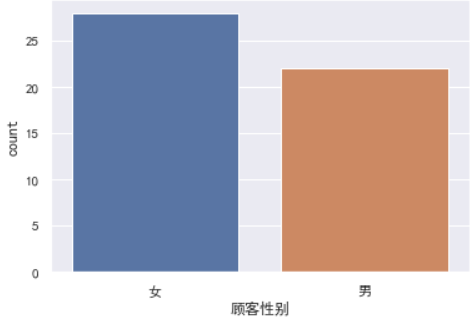
sns.countplot(data=df,x='顾客性别');
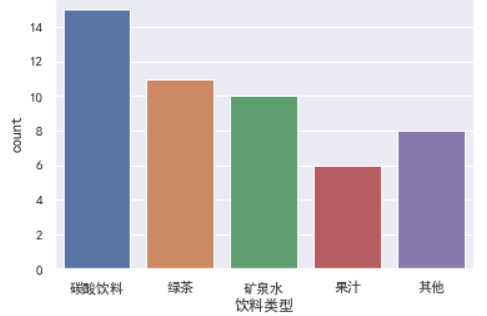
sns.countplot(data=df,x='饮料类型');
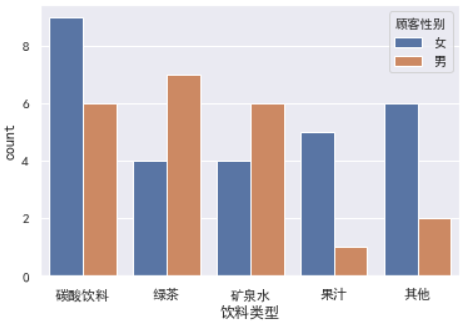
sns.countplot(data=df,x='饮料类型',hue='顾客性别');
-
饼图
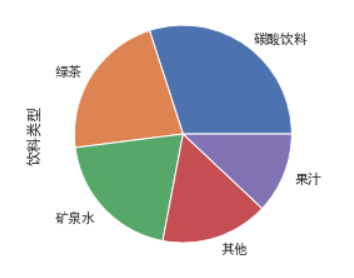
饼图(pie chart)是用圆形及圆内扇形的角度来表示数值大小的图形,它主要用于表示一个样本(或总体)中各组成部分的数据占全部数据的比例.
df['饮料类型'].value_counts().plot(kind='pie');
-
-
-
-
-
-
数据分组的主要目的是观察数据的分布特征。数据分组的方法有单变量值分组和组距分组两种。
-
单变量值分组是把每一个变量值作为一组,这种分组通常只适合离散变量,且在变量值较少的情况下使用。
-
在连续变量或变量值较多的情况下,通常采用组距分组。它是将全部变量值依次划分为若干个区间,并将一个区间的变量值作为一组。在组距分组中,一个组的最小值称为下限,一个组的最大值称为上限。采用组距分组时,需要遵循不重不漏的原则。为解决不重的问题,统计分组时习惯上规定“上组限不在内”,即当相邻两组的上下限重叠时,恰好等于某一组上限的变量值不算在本组内,而计算在下一组内。
-
分组步骤:1.确定组数 2.确定各组的组距 3.根据分组编制频数分布表
#分组,组距为10,组数为10 bins_list = pd.cut(df['销售量'],bins=range(140,240,10))
-
-
-
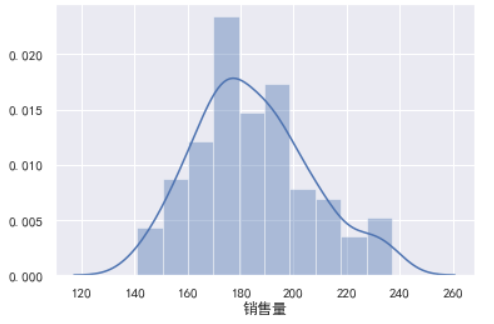
直方图
sns.distplot(df['销售量']);
-
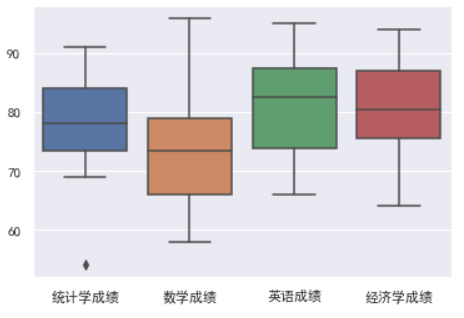
箱线图
df = pd.read_excel('data/3.数据的图表展示/例题/例3.1.xlsx') #导入数据 sns.boxplot(data=df);
-
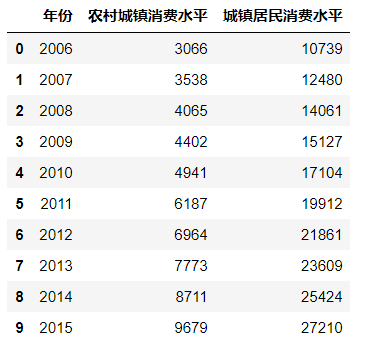
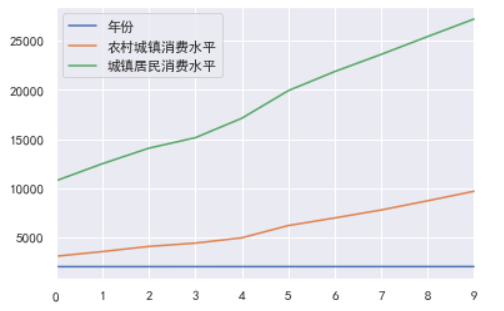
线图
df = pd.read_excel('data/3.数据的图表展示/例题/例3.8.xlsx') #导入数据 df
df.plot();
-
散点图
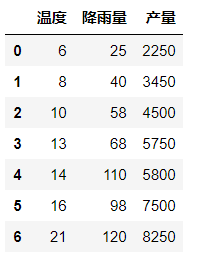
df = pd.read_excel('data/3.数据的图表展示/例题/例3.9.xlsx') #导入数据 df
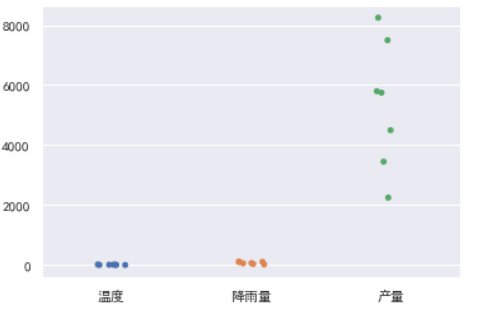
sns.stripplot(data=df);
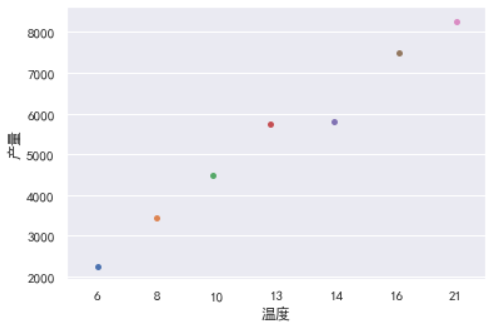
sns.stripplot(x=df['温度'],y=df['产量']);
-
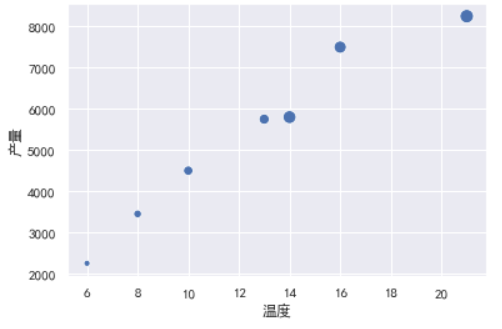
气泡图
sns.scatterplot(x=df['温度'], y=df['产量'], s=df['降雨量']);
-
-