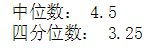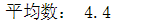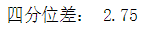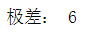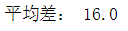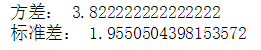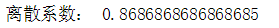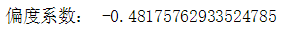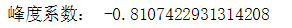数据分布的特征可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
-
集中趋势是指一组数据向某一中心值靠拢的程度,它反映了一组数据中心点的位置所在。
-
众数
众数是一组数据中出现次数最多的变量值,用M。表示。众数主要用于测度分类数据的集中趋势,也可作为顺序数据以及数值型数据集中趋势的测度值。
data = np.random.randint(1,10,10) print(data) data = pd.Series(data) data.mode()
-
中位数与分位数
中位数是一组数据排序后处于中间位置上的变量值,用M.表示。
m_0 = data.median() m_1 = data.quantile(q=0.25) #四分位数 print('中位数:',m_0) print('四分位数:',m_1)
-
平均数
平均数也称为均值,它是一组数据相加后除以数据的个数得到的结果。
mean = data.mean() print('平均数:',mean)
-
-
数据的离散程度是数据分布的另一个重要特征,它反映的是各变量值远离其中心值的程度。数据的离散程度越大,集中趋势的测度值对该组数据的代表性就越差;离散程度越小,其代表性就越好。
-
四分位差
四分位差是上四分位数与下四分位数之差,四分位差反映了中间50%的数据的离散程度,数值越小,说明中间的数据越集中;数值越大,说明中间的数据越分散。四分位差不受极值的影响。
qd = data.quantile(q=0.75) - data.quantile(q=0.25) print('四分位差:',qd)
-
极差
一组数据的最大值与最小值之差称为极差,也称全距,用R表示。
R = data.max() - data.min() print('极差:',R)
-
平均差
平均差也称平均绝对离差,它是各变量值与其平均数离差绝对值的平均数。
m_d = (data - data.mean()).apply(lambda x: x if x >0 else -x).sum() print('平均差:',m_d)
-
方差/标准差
方差是各变量值与其平均数离差平方的平均数。它在数学处理上通过平方的办法消去离差的正负号,然后再进行平均。方差的平方根称为标准差。
var = data.var() std = data.std() print('方差:',var) print('标准差:',std)
-
标准分数
变量值与其平均数的离差除以标准差后的值称为标准分数,也称标准化值或z分数。
(data - data.mean()) / data.std()
-
离散系数
离散系数也称为变异系数,它是一组数据的标准差与其相应的平均数之比。
v_s = data.var() / data.mean() print('离散系数:',v_s)
-
-
-
偏态系数
如果一组数据的分布是对称的,则偏态系数等于0;如果偏态系数明显不等于0,表明分布是非对称的。若偏态系数大于1或小于一1,称为高度偏态分布;若偏态系数在0.5~1或一1~-0.5之间,则认为是中等偏态分布;偏态系数越接近0,偏斜程度就越小。
skew = data.skew() print('偏度系数:',skew)
-
峰态系数
峰态通常是与标准正态分布相比较而言的。如果一组数据服从标准正态分布,则峰态系数的值等于0;若峰态系数的值明显不等于0,则表明分布比正态分布更平或更尖,通常称为平峰分布或尖峰分布。
kurt = data.kurt() print('峰度系数:',kurt)
-