{kind=link}
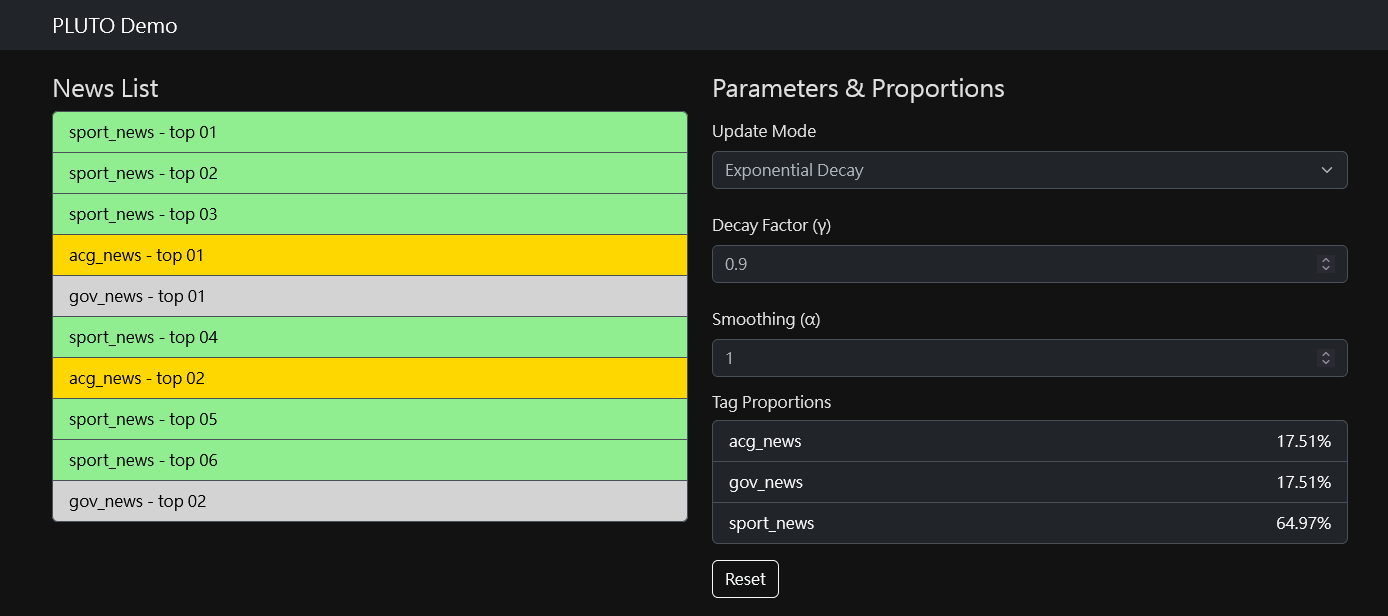
PLUTO (Probabilistic Learning Using Tag-based Ordering) is a tag-driven reranking algorithm designed for lightweight, client-side personalization. PLUTO employs a simple yet effective probabilistic method to adaptively reorder content based on user interaction feedback, without requiring server-side computation, large-scale models, or complex infrastructure. It is particularly suited for edge computing environments, privacy-conscious deployments, and rapid prototyping.
PLUTO is based on a variant of the Roulette Wheel Selection [1] algorithm, a well-established probabilistic selection technique commonly used in genetic algorithms and the Multi-Armed Bandit Problem (see Appendix B). The core idea is to assign probabilistic weights to content categories (tags) based on user interaction history and use these weights to progressively steer content ranking in a personalized direction.
Let there be a fixed set of categories (tags):
Let the interaction counts (e.g., clicks) for each tag be represented by:
To smooth cold-start behavior and ensure every tag has a non-zero chance of selection, we introduce a constant
These probabilities serve as weights in the Roulette Wheel Selection process.
Given a candidate item pool where each item is associated with one or more tags from
-
Tag Grouping: Group the items by their associated tag. Each group is sorted by original relevance (e.g., score or timestamp).
-
Probabilistic Tag Sampling: For a fixed rerank length
$k$ , repeat the following$k$ times:- Draw a tag
$t_i \sim \text{Categorical}(P)$ using roulette wheel selection. - From the head of tag group
$t_i$ , remove and append the top item to the final list.
- Draw a tag
-
Output: The final reranked list is composed by concatenating the selected items in the order drawn.
This sampling-based reranking is greedy and proportional, ensuring that tag groups are not overrepresented while preserving all input items.
PLUTO supports two common update strategies for user click feedback. When an item is clicked, each tag associated with the item is treated as having been clicked once. That is, all
-
Fixed Window Length
$N$ Only the most recent
$N$ user clicks are retained. For category$t_i$ , the click count$c_i$ is computed as the number of times$t_i$ appears among the tags of the last$N$ clicked items, multiplied by a learning rate$T$ :$c_i = T \times \text{count}_N(t_i)$ where
$\text{count}_N(t_i)$ denotes the number of times tag$t_i$ appeared in the tags of the last$N$ clicked items. -
Exponential Decay
$\gamma$ All tag click counts are decayed over time. When an item is clicked, every tag associated with it is treated as having been clicked once. The update rule is:
$c_i \leftarrow \gamma \cdot c_i + \delta_{\text{click}}(i) \times T$ where:
-
$\gamma \in (0,1)$ is the decay factor. -
$\delta_{\text{click}}(i) = 1$ if tag$t_i$ is among the tags of the clicked item; otherwise, 0.
-
PLUTO offers a pragmatic balance between interpretability and functionality. It supports real-time, on-device personalization by modeling user preferences as an adaptive multinomial distribution over tags. Its benefits include:
-
White-box simplicity and transparency: Parameters
$\alpha, T, N, \gamma$ are human-interpretable and directly influence behavior. The algorithm is straightforward to audit and debug. - Preservation of list completeness: PLUTO does not drop or filter out items, resulting in a smoother user experience when introduced.
- No server dependency: Operates in environments without backend access or centralized logging.
Additionally, PLUTO's hyperparameters can be analytically or numerically tuned in reverse based on business constraints. For instance, given a minimum acceptable visibility rate for all tags (e.g., 5%), one can derive the necessary smoothing factor
However, PLUTO has several limitations:
- Limited modeling capacity: It relies entirely on tags; tag quality defines its upper bound.
- Susceptibility to noisy feedback: Click data can be sparse or ambiguous.
- Lack of contextual awareness: No modeling of session-based intent or temporal dynamics.
- Bias toward early feedback: Tags with early engagement may dominate without proper decay or normalization.
- Dependence on initial sorting: PLUTO only learns tag proportions; another ranking signal is needed to sort within each tag group.
PLUTO is well-suited to content systems with limited recall scope, including:
- News readers or RSS feeds (recent clusters matter most)
- E-commerce carousels (only a group of products shown at once)
- Trending or hot lists (popularity matters most)
PLUTO is also ideal for services introducing personalization for the first time:
- No user data available
- No budget for complex systems
- Large shifts in ranking could disrupt user habits
- Non-engineering stakeholders prefer interpretable algorithms
These services often already have popularity or recency sorting and tag metadata. PLUTO aligns well with these foundations. In early phases, content-based tagging can drive personalization without building new infrastructure. Later, user data can be used to dynamically generate or tune tags (via clustering, user segmentation, etc.), enabling hybrid and collaborative filtering models. As the system evolves, logged tag-click pairs, preference models, and click-through rates can support deeper personalization.
PLUTO demonstrates how a classic probabilistic method like roulette wheel selection can be reimagined for real-time, tag-based recommendation reranking. It combines a lightweight formulation with interpretable mechanics, making it useful for edge applications, prototypes, and privacy-aware deployments. While it does not compete with deep personalization models in precision, it excels in speed, simplicity, and usability — qualities often undervalued in early-stage systems or constrained environments.
Its "good enough" philosophy makes it ideal for MVPs or scenarios where responsiveness, explainability, and privacy are priorities.
[1] Roulette Wheel Selection for Multi-Armed Bandit Problems | James D. McCaffrey
Given a minimum acceptable tag selection probability
Assuming the worst case where some tags receive no clicks over
Example:
Under exponential decay, the effective cumulative contribution of past interactions converges to a geometric series:
To ensure unclicked tags still hold at least
Example:
These bounds ensure that even unclicked tags retain sufficient representation, thus preventing overspecialization or starvation.
Note: The reverse derivation formula above assumes a simplified scenario where each click event affects only a single tag. In practice, if each click can update multiple tags (i.e., items are associated with multiple tags), the denominator should be adjusted to reflect the maximum possible total tag score across the last
$N$ events. Specifically, the denominator becomes$N T (n-1) + n \alpha$ and$\frac{T}{1-\gamma} (n-1) + n \alpha$ respectively in the worst case, where all tags except the one in question are updated in every event.
Online exploration and optimization problems like reranking often resemble the Multi-Armed Bandit Problem. PLUTO also shares some similarities with classic Bandit algorithms such as Thompson Sampling.
However, the difference lies in their objectives:
- Bandit algorithms aim to maximize utility, often converging to a single best option.
- PLUTO aims to learn preference distributions, continuously representing a user's interests across multiple tags.
| System | Outcome |
|---|---|
| PLUTO | Learns preference ratio: e.g., ACG:Sports:Gov = 5:4:1 |
| Bandit | Learns best category: e.g., ACG only |
In many real-world scenarios, users have multiple interests. Therefore, learning a distribution is more appropriate than converging to one best category. Bandit algorithms can still be adapted (e.g., contextual bandits), but PLUTO’s formulation is often simpler and more flexible for personalized ranking.
This contrast also appears in reinforcement learning:
- Value-based (e.g., Q-learning) learns optimal actions.
- Policy-based (e.g., Policy Gradient) learns probabilities of choosing each action.
In domains requiring diversity or stochasticity (e.g., games, personalization), learning a distribution (as PLUTO does) often yields more robust behavior.