csTimer - 魔方竞速训练专用计时器,这是一个 canvas 图片爬虫例子
HTML 的 canvas 标签生成的图片,使用平常获取图片URL下载是行不通的。
https://pan.bigdataboy.cn/#/s/wjHw
- 模仿公式
- 公式对应的
canvas图片
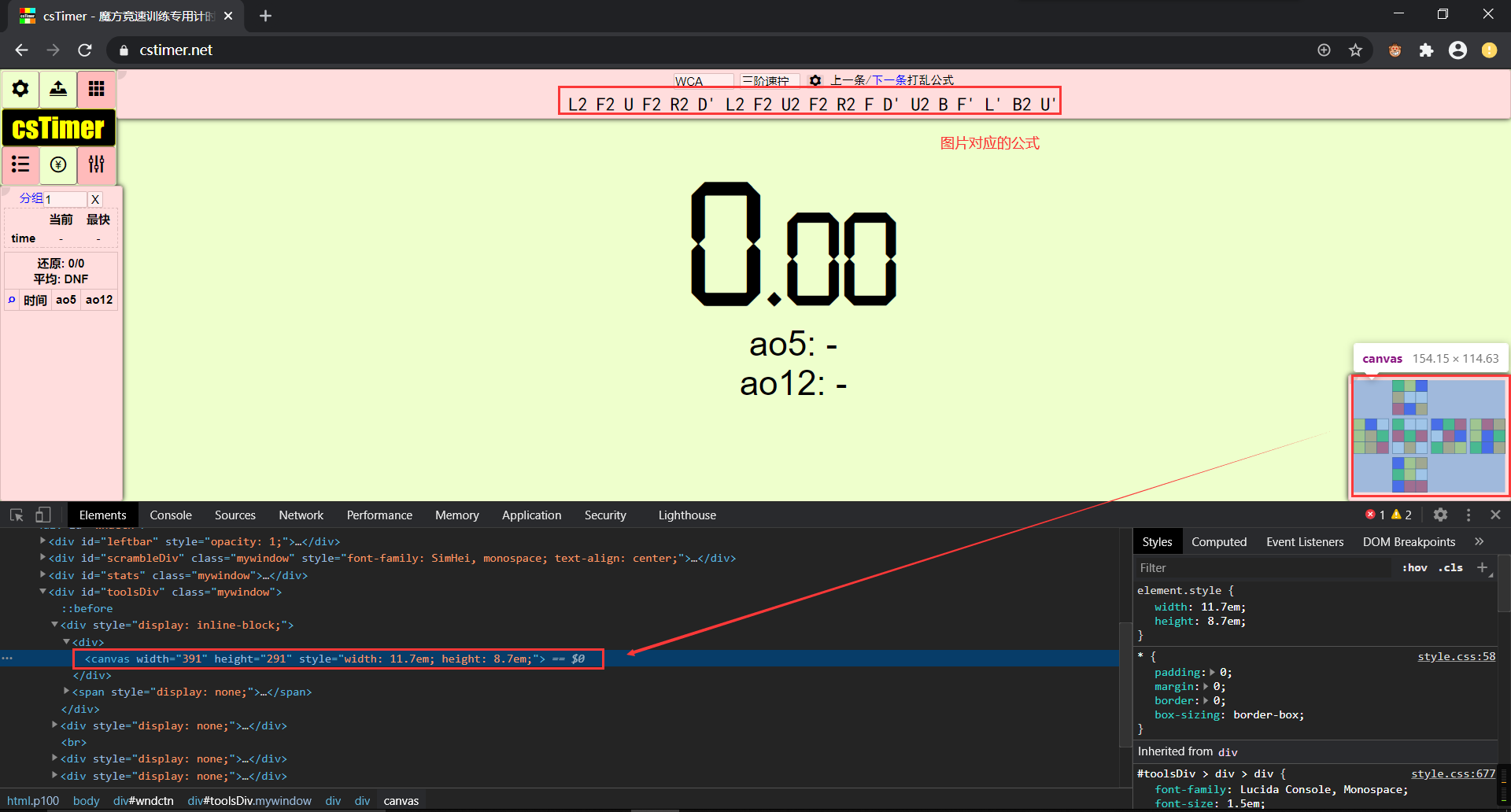
- Python
- selenium
爬取
canvas的思路是执行canvas.toDataURL("image/png")方法获取图片的base64编码,再转码为bytes,然后保存在本地
class Main:
# 图片保存路径
IMG_PATH = "./img/"
# 公式保存文件
FILE = "a.txt"
# 保存公式的个数
COUNT = 5000
# 保存速度
SPEED = 0.1 # None:无限制。支持浮点数
def __init__(self):
#TODO 打开网站
def save(self, i):
#TODO 保存 公式 及 图片
def run(self):
#TODO 运行类def __init__(self):
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 隐藏自动化测试
# options.add_argument("--headless") # 注释掉,就无需打开浏览器窗口
# 加载网站
self.bro = webdriver.Chrome(executable_path="./chromedriver_win32/chromedriver.exe", options=options)
self.bro.get(url="https://www.cstimer.net/")
# 检查网页是否加载完成
WebDriverWait(self.bro, 60).until(
EC.presence_of_element_located((By.XPATH, '//div[@id="leftbar"]/div[@class="mybutton c6"]/div/span[2]')))
# 判断图片框是否显示
if not self.bro.find_element_by_id('toolsDiv').is_displayed():
# 点击显示图片
self.bro.find_element_by_xpath('//div[@id="leftbar"]/div[@class="mybutton c6"]/div/span[2]').click() def save(self, i):
# 保存公式
formula = self.bro.find_element_by_xpath('//div[@id="scrambleTxt"]/div').text
with open(self.FILE, mode='a+', encoding="UTF-8") as f:
text = f"{formula}----{i}\n"
logger.info(text)
f.write(text)
# 保存图片
JS = 'return document.getElementById("toolsDiv").childNodes[0].childNodes[0].childNodes[0].toDataURL("image/png");'
img_base64 = self.bro.execute_script(JS).split(',')[1] # 执行js文件得到带图片的 base64 编码
img_bytes = base64.b64decode(img_base64) # 转为bytes类型
path = f"{self.IMG_PATH}{i}.png"
logger.info(path)
with open(path, 'wb') as f: # 保存图片到本地
f.write(img_bytes)def run(self):
i = 1
while self.COUNT >= i:
self.bro.find_element_by_xpath('//div[@class="title"]/nobr[2]/span[2]').click()
self.save(i)
if self.SPEED:
sleep(self.SPEED)
logger.info(f"延迟: {str(self.SPEED)} 中....")
i += 1
logger.info(f"爬取完成")if __name__ == '__main__':
mian = Main()
mian.run()