Machine Learning Model using Convolutional Architecture to naturally rank similarity between given inputs in order to make correct predictions given only single example of a new character image class.
- Model can make predictions given only single image of a new class.
- Prediction classes can be added/removed without need for retraining the model.
Used Omniglot dataset which is a collection of 1623 hand drawn characters from 50 different alphabets. For every character there are just 20 examples, each drawn by a different person. Each image is a gray scale image of resolution 105x105.
Implementation is broadly divided into 4 steps:
- Loading dataset
- Mapping the problem to binary classification task
- Model Architecture and Training
- Testing
The datafiles have this format :
main_file -> alphabets(different languages) -> letters(for particular alphabet) -> 20 images for each letter
function loadimgs groups all letter images in X, marks corresponding labels in y, and maps the ranges of letter's labels in an alphabet in lang_dict.
Sample example:
Let X.shape is (964,20,105,105),this means we have 964 characters (or letters or categories) spanning across 30 different alphabets. For each of this character, we have 20 images, and each image is a gray scale image of resolution 105x105.
Also Y.shape is (19280,1) signifies Total number of images = 964 * 20 = 19280. All the images for one letter have the same label.
Similarly for lang_dict['Sanskrit'] = [110, 136], denotes letters of Sanskrit alphabet have labels ranging from 110 to 136 (inclusive).
We can map this problem into a supervised learning task where our dataset contains pairs of (Xi, Yi) where ‘Xi’ is the input and ‘Yi’ is the output.
Xi contains the pair of images
Yi = 1 when both images belongs to same letter, else 0.
Two CNN architecture each having 4 conv layers followed by maxpool layers except the last one, which after flattening is followed by fully connected layer of size 4096. Both networks are integrated by taking difference of outputs for fully connected layer, which is fed to final output layer with sigmoid activation.
Pictorial representation of network:
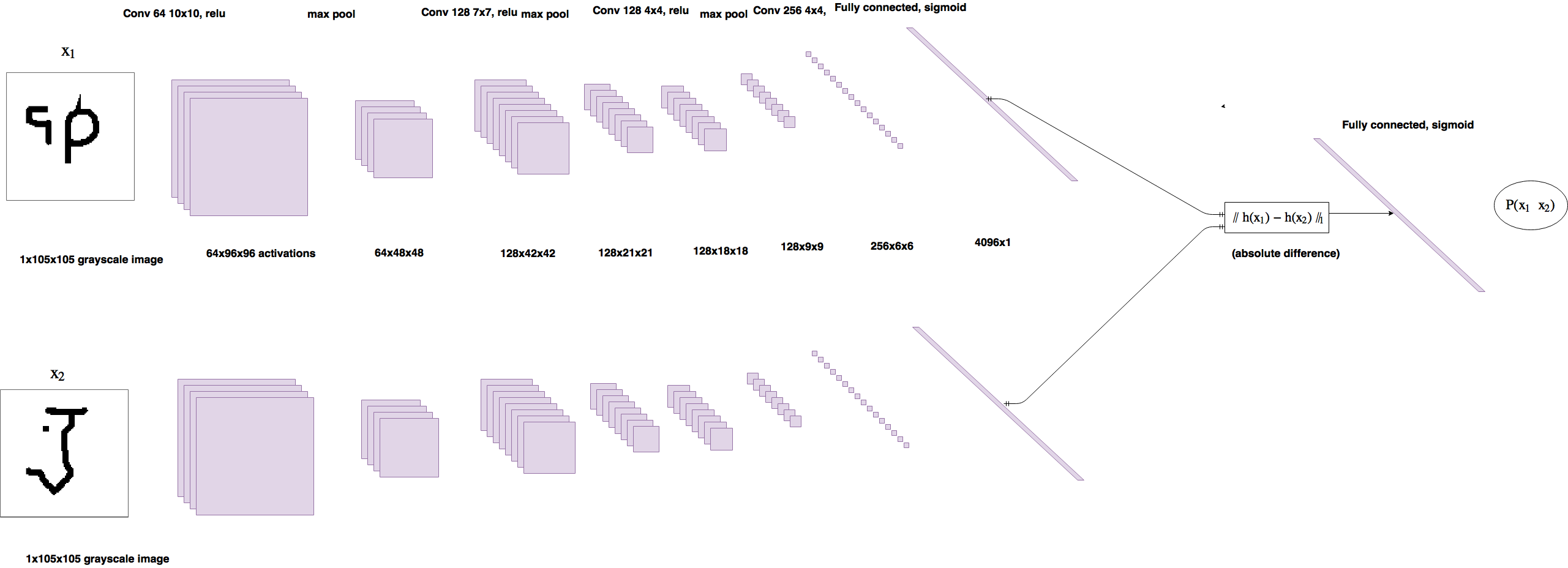
Model was trained for 20000 iterations with batch size of 32. Weights were saved and validation performance was measured every 250 iterations.
Model was tested on 20 way one shot tasks from validation dataset. Accuracy was way better(80+%) than baseline models like nearest neighbour.