This repository contains the SpurBreast dataset, a curated real-world breast MRI dataset specifically designed to study spurious correlations in medical imaging. SpurBreast extends the DUKE Breast Cancer dataset with carefully constructed training/validation splits that deliberately introduce or avoid spurious correlations. The dataset was proposed in the paper SpurBreast: A Curated Dataset for Investigating Spurious Correlations in Real-world Breast MRI Classification, published at the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2025).
Datasets can be downloaded using this link, and should be extracted into the /data folder.
In the /src folder, the file cls_dataset.py contains a bare-bones implementation of a PyTorch dataset that you can use directly.
This file provides the SpurBreastDataset class, which can be initialized as follows:
from cls_dataset import SpurBreastDataset
data_folder = '../data'
spurious_feature = 'field_strength'
aug = ... # PyTorch transformations
tr_dataset = SpurBreastDataset(data_folder, spurious_feature, 'training', aug)
val_dataset = SpurBreastDataset(data_folder, spurious_feature, 'validation', aug)
ts_dataset = SpurBreastDataset(data_folder, spurious_feature, 'test', aug)Using this dataset, you can train your own model by specifying one of the following spurious features:
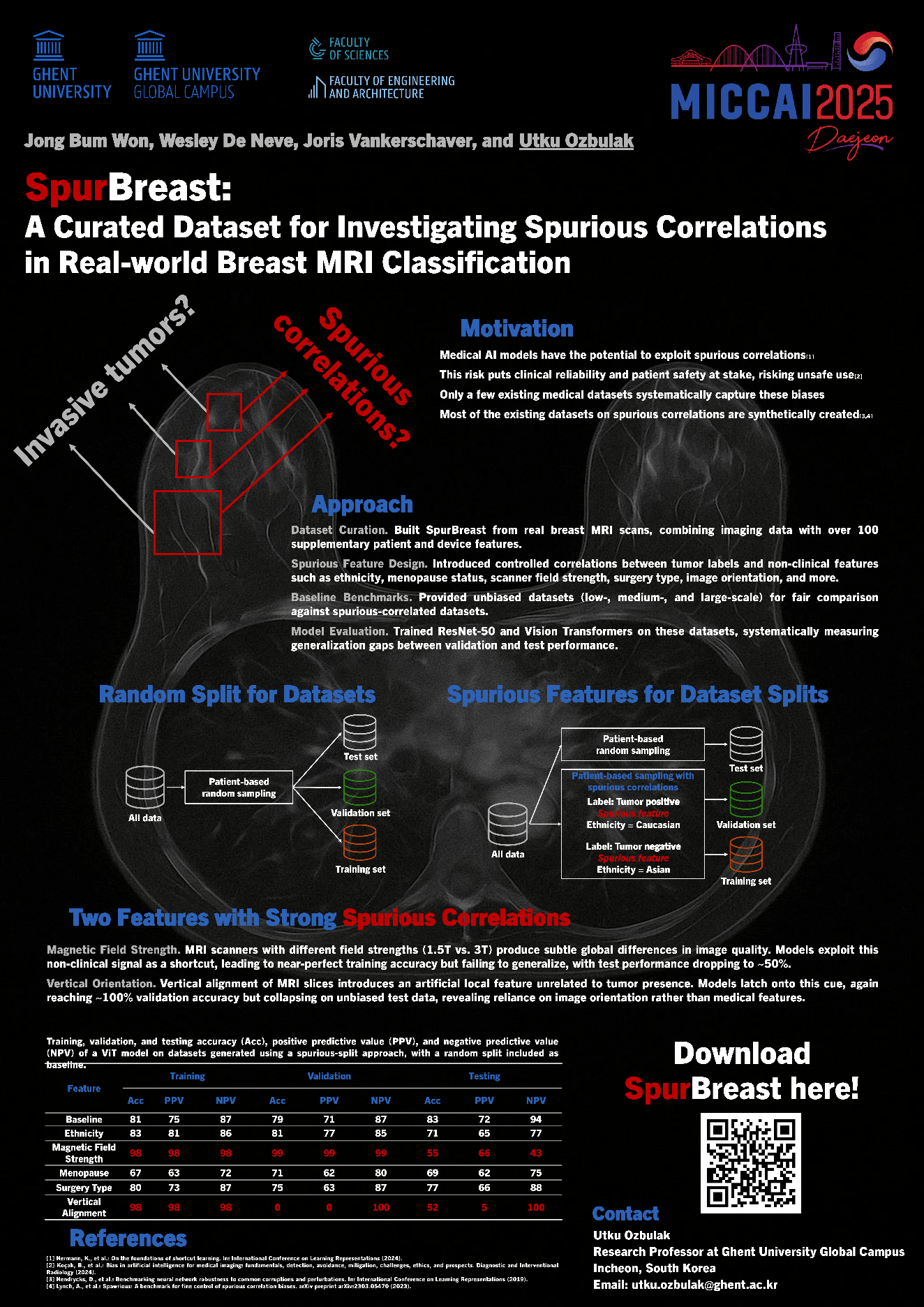
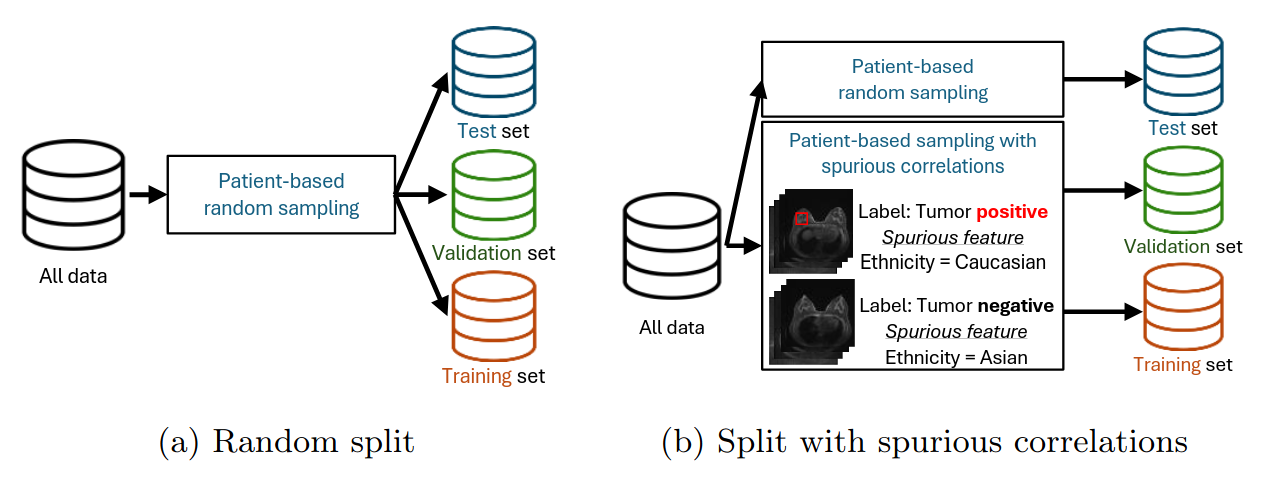
features = ['field_strength', 'menopause', 'race_and_ethnicity', 'surgery_type', 'vertical_flip']Out of the three datasets (train, validation, test), the training and validation splits contain spurious correlations, while the test split does not. This setup lets you evaluate your model on data that shares the same spurious correlations as the training set as well as on data free of those correlations.
Our experiments show that field_strength and vertical_flip (vertical orientation) introduce the strongest spurious signals. Other features (menopause, race_and_ethnicity, surgery_type) have weaker or minimal effects.
We also provide several splits that are created with patient-based random sampling which do not contain spurious correlations. For those, you can call the same class with one of the following splits.
baseline_splits = ['baseline_high', 'baseline_mid', 'baseline_low']Please be mindful that the DUKE dataset is licensed under Creative Commons Attribution-NonCommercial 4.0 International License (CC BY-NC 4.0).
BY – Attribution: You must give credit to the original creator.
NC – NonCommercial: You can’t use it for commercial purposes.
As such, our extension, SpurBreast is also licensed using the same terms.
This work is a research output from Ghent University, Belgium and Ghent University Global Campus, South Korea.
For inquiries, please create an issue or contact Utku Ozbulak: utku.ozbulak@ghent.ac.kr