Speeding up GPU clustering using smarter download strategy and memory allocations#4677
Conversation
|
Nice idea, and the flame graphs look promising
|
|
Thank you for the kind and detailed feedback, @mvieth - that was very helpful to me! I will address the comments and update the PR. |
|
Thank you again for your detailed comments! I tried to address these comments as follows:
I hope this address all the comments you made and that I did not forget anything. Is there anything else you suggest looking at? I also thought more about the problem and have two other ideas for improving it: According to the flamegraph, 9 percent of the time is spent in malloc inside the create function of the Apart from resizing the array, copying data from the device to the host requires the most time (about 2/3 in the current form). Looking at lines 149ff, I think we could avoid copying the data as the only relevant computation is obtaining the indices from Do you think any of these ideas are worthwhile to pursue? Or would you alternatively suggest working on other areas of the GPU section? |
|
I'm sorry to see the build partially failing. Could somebody kindly help me understanding why that happened? I looked through the logs and found only one statement that might report an error: However, the build continues for a while afterwards and I suspect I misinterpret the error. I am grateful for any hints or suggestions to understand the build results! |
|
So a speed-up of 2.2 and 1.5 respectively - that is really nice. |
|
Thank you very much, @mvieth, for your detailed and thoughtful comments - they again helped me understand the problem much better! I'm surprised you did not experience a significant change in run-time. With my configuration, the run-time changed almost monotonically. I will report detailed benchmarks again. Your comment that we download more data than necessary was striking to me, I did not realize this first. For a sampled iteration of the nested for loop the selected indices P.S. Thanks for running the build again - its reassuring to see that not only my computer runs out of memory when building PCL when using all possible cores. |
|
I'm just testing it out as well. For each query points, the radius search is performed, but the results are not accumulated and hence, it never finds the required sizes of clusters. Also, it seems, with my preliminary tests of setting it to 200 (No GPU activity with the pointcloud / parameters I use), the "CPU implementation of the GPU algorithm" is faster than the euclidian clustering in pcl_segmentation (using a K-D tree). Some more investigation is required. |
|
Thanks for the detailed and very helpful comments, @larshg! Your comments about the difference between the CPU and GPU version are indeed intriguing and I am happy to investigate it more thoroughly! |
|
@larshg Thank you again for pointing out that the obtained clusters are a function of the GPU offloading threshold! I did verify this, which left me puzzled for a while. I adjusted the scope of the loop you pointed out, but that didn't help. I will try to figure out what is going on and then write again. @mvieth I refrained from benchmarking the run-time of the algorithm as a function of the offloading threshold. I will first try to understand why changing the threshold causes the results to differ and then measure run-time performances. @kunaltyagi Thanks for the comments! I did adjust the code in response to your observations, and I think it improves the code. At all three of you: Thank you so much for taking a look at this PR and for guiding me through the process - this is indeed a pleasure! |
|
First: Thank you all again for the excellent feedback so far! It is really a pleasure to work on this. I continued working on the issue and made progress on the program's efficiency. As @mvieth suggested, we currently download potentially too much data from the device to host. A more judicious download gives us speed gains of a factor of 3. I updated the PR to document the ideas in code. However, I do not think this code is pretty, and I am not sure if it's a good idea to merge it. To keep the discussion focused, I opened another issue to discuss expanding the API of the DeviceArray to allow users to download data more effectively. Here are some performance benchmarks (taken for the pcd test data)
The flamegraphs reflect the timing updates too. The graph still highlights further possibilities for improvement of the GPU version. However, the CPU code dominates the timing for the first time :-). I realize that the problem of different results depending on the threshold parameter persists! Thanks again for highlighting this, @larshg! Although I am thinking about it, I am still tapping a bit in the dark but will keep trying. What do you think about the changes and what are open questions for you? P.S. I cannot use a few of the test datasets because FLANN fails on the CPU. These are: table_scene_mug_stereo_textured, office1d, or five_people. The (abbreviated) error is "Invalid (NaN, Inf) point coordinates given to radiusSearch!"' failed. I have looked for an issue but didn't see one. Does somebody know an issue? |
|
Ha! I think things are falling in place! Thank you again, @larshg , for identifying that the number of clusters changes as the offloading parameter changes. As you speculated, not all found indices found inside the method |
|
Yes, thats pretty much the same thing I thought would be required. Not sure if you can use a And maybe use |
|
Thank you, @kunaltyagi, for reviewing the PR - that was very helpful indeed! I updated the PR accordingly. Thank you also very much, @larshg! I replaced all instances of What are your opinions about placing the cuda interaction into the #include <cuda_runtime_api.h>
#include <cuda.h>
...
const std::size_t bytes = (sizes[qp]) * sizeof(int);
cudaMemcpy(&tmp[0], pdata, bytes, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();I think all these lines could be placed inside a function overloading the |
|
Thank you, @kunaltyagi , for your comments - they were very helpful for me! |
 kunaltyagi
left a comment
kunaltyagi
left a comment
There was a problem hiding this comment.
Just some thoughts about 1 final memory allocation
| for(int idx : data) | ||
| { | ||
| for(int qp_r = 0; qp_r < sizes[qp]; qp_r++) | ||
| { | ||
| if(processed[data[qp_r + qp * max_answers]]) | ||
| continue; | ||
| processed[data[qp_r + qp * max_answers]] = true; | ||
| queries_host.push_back ((*host_cloud_)[data[qp_r + qp * max_answers]]); | ||
| found_points++; | ||
| r.indices.push_back(data[qp_r + qp * max_answers]); | ||
| } | ||
| } | ||
| if(processed[idx]) | ||
| continue; | ||
| processed[idx] = true; | ||
| queries_host.push_back ((*host_cloud_)[idx]); | ||
| found_points++; | ||
| r.indices.push_back(idx); | ||
| } |
There was a problem hiding this comment.
Oh, sorry, I tried to fix it! Is it correct now? I have a question though: When I clang-format the file gpu_extract_clusters.hpp many lines of the file change. Am I doing something wrong or does the same maybe also happen to you too?
There was a problem hiding this comment.
gpu module isn't formatted yet. So your experience is correct. The plugin I use allows me to format only a selection of lines instead of all the lines in the file.
You can either:
- use similar settings for some plugin in your fav editor
- create an additional formatting commit (at the start or end) so we can skip that/select that easily during code-review
There was a problem hiding this comment.
Ha - thanks for pointing out this feature in vim clang-format! I always only formatted the entire buffer, never a few lines. Shall I maybe make a batch PR clang-formatting the GPU codebase?
kunaltyagi
left a comment
There was a problem hiding this comment.
LGTM otherwise :)
Thanks @FabianSchuetze for bearing with us
It was a pleasure to work on it - thank you so much for your support @kunaltyagi ! I have another question as this issue comes to an end: I would like to continue working on the GPU code. Issues #4443 or #2218 seem interesting to me. Alternatively, the GPU code seems to lack a correspondence estimation, and I would be happy to work on this. I would be thrilled to see a GPU version of the ICP algorithm and think this should be the next step. Do you have an idea of which feature/issue to prioritize? |
|
Puha! I think we are getting closer to an end. Thanks to the expansion of the device array API, we can avoid the Cuda calls in the segmentation module spotted by Lars. |
|
Apart from 3 really minor things, LGTM. |
|
Thank you, Kunal and Lars, for the review! Lars, you are eagle-eyed! I did apply most of the changes you suggested - thank you. |
|
Just tested it. I went from something like 38 seconds, load of spam, faulty clusters, to 8 seconds, minimal spam, correct clusters, with my test pointcloud with about 120k points, thats segmented into 28 clusters with size of 3000-10.000 points. I noticed that line is still verbose: Could you fix this one as well 😄 ? |
|
Thank you, Lars, for testing the program and for your feedback. Your message is bittersweet! I'm glad the results of the program itself were OK. Nevertheless, it would be wonderful to have a GPU version that performs faster than the CPU version. I will take a look at some GPU KDTree implementations for inspiration. Anyway - the noisy info got banished to the PCL_DEBUG macro, and it shan't be seen anymore during normal operation. Thanks for the feedback! |
|
@mvieth Do you want to take a look? Or we can go ahead and squash-merge this |
|
Thanks for approving, Lars and Kunal! |
|
I had a quick look over the code, everything seems fine. And it definitely promises a great speedup, even if it might still not be able to compete with the pure CPU version. Thank you for working on this! |
… allocations (PointCloudLibrary#4677) * remove costly memory allocation * addresses comments * stylistic changes * economical download of data from device to host * tries to resolve bug of different cluster sizes * removed comments and address PR review * try to address review comments * exploiting symmetry * formatting and auto * placed function in source file * placed function again in namespace pcl::detail * moved declaration to hpp file * compatible with new device array api * remove duplicate function - compiles but segfault * runs without segfault * cosmetic changes * removed noisy info * Add newline for the debug macro Co-authored-by: Kunal Tyagi <tyagi.kunal@live.com>
… allocations (PointCloudLibrary#4677) * remove costly memory allocation * addresses comments * stylistic changes * economical download of data from device to host * tries to resolve bug of different cluster sizes * removed comments and address PR review * try to address review comments * exploiting symmetry * formatting and auto * placed function in source file * placed function again in namespace pcl::detail * moved declaration to hpp file * compatible with new device array api * remove duplicate function - compiles but segfault * runs without segfault * cosmetic changes * removed noisy info * Add newline for the debug macro Co-authored-by: Kunal Tyagi <tyagi.kunal@live.com>
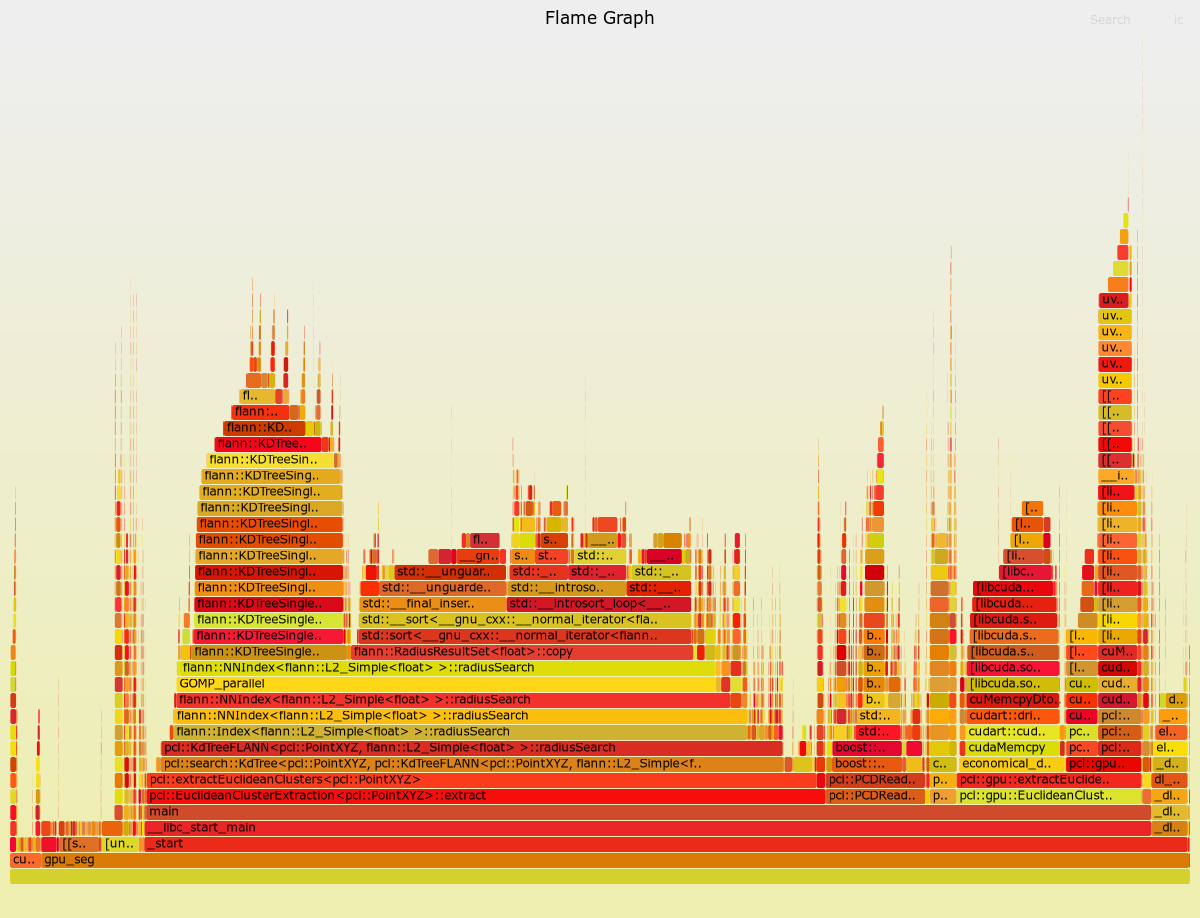
I stumbled upon the same issue mentioned in #2703 while familiarizing myself with the GPU-related codebase of PCL. A CPU flamegraph showed about 1/3 of the runtime is spent on resizing a vector:
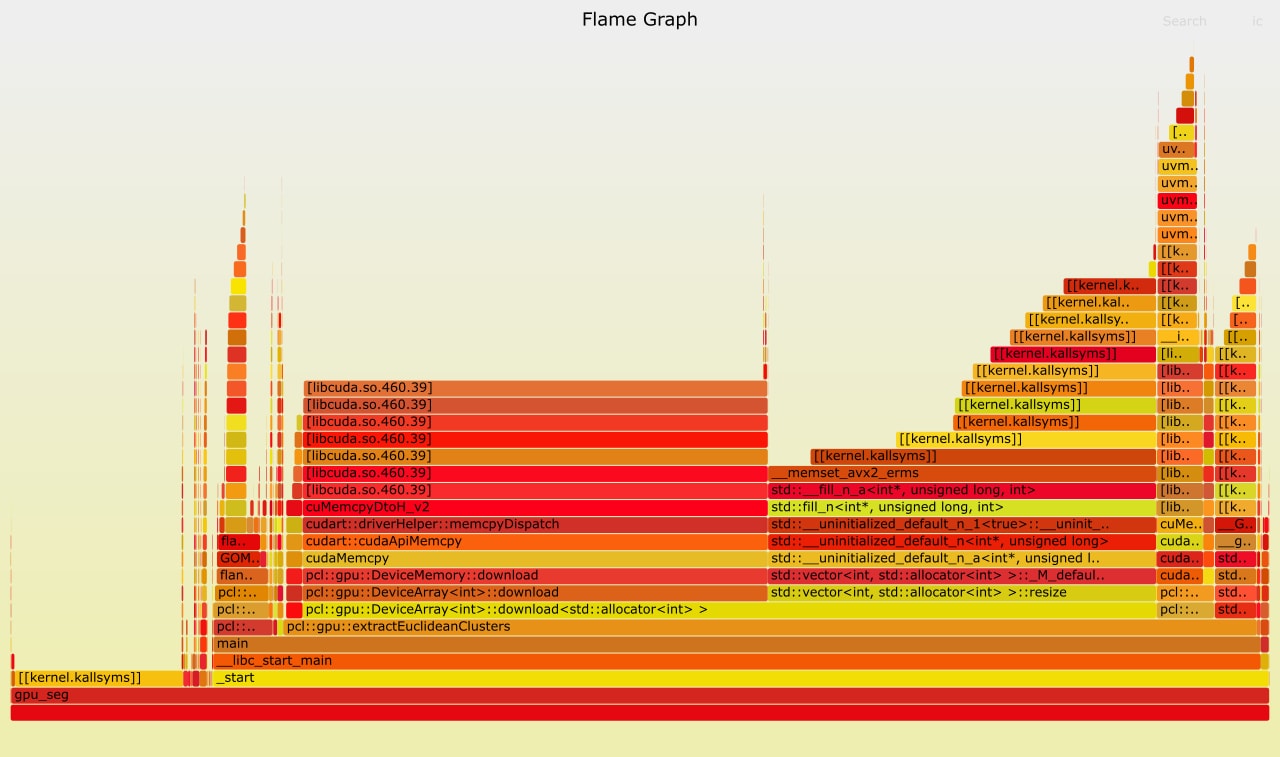
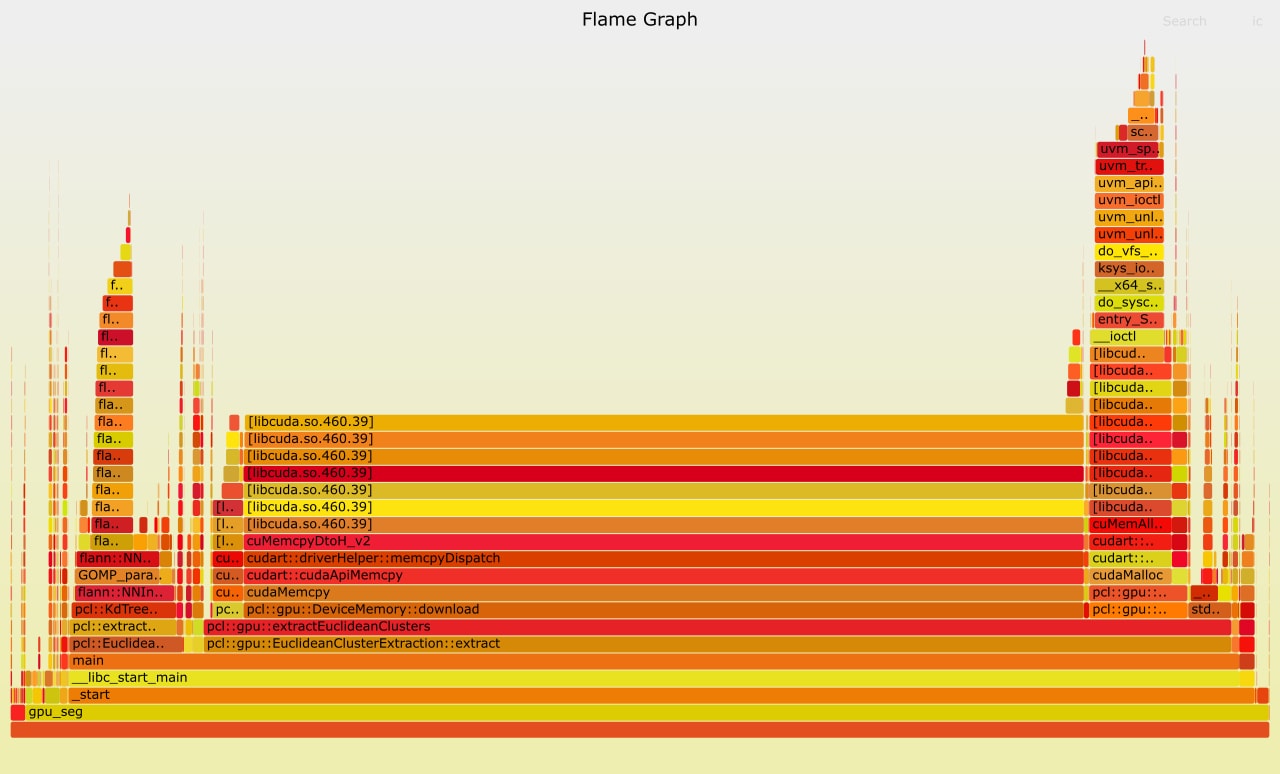 I tried to optimize the Cuda memcopies that also incur significant times by using pinned host memory, but that did not lead to a noticeable improvement. The GPU code is still significantly slower than the CPU version, though. I believe this is due to the sequential nature of the program, and data copies between the host and device memory.
I tried to optimize the Cuda memcopies that also incur significant times by using pinned host memory, but that did not lead to a noticeable improvement. The GPU code is still significantly slower than the CPU version, though. I believe this is due to the sequential nature of the program, and data copies between the host and device memory.
The resize function is located in the device_array.hpp codebase. The arrays are constructed in the loop (line 100) of gpu_extract_custer.hpp. Pre-allocating the array to the maximum possible size can mostly eliminate the memory allocations as documented by the flamegraph with the revised code:
I would be happy to work more on this issue if further PRs are welcome in this field. Maybe somebody also has an idea for improving GPU-based segmentation or other ideas to work on the GPU-related codebase of PCL!
P.S. The function pcl::gpu::extractEuclideanClusters is verbose by default, should we maybe also change this?