Avoid overflow in statitics.mean#7426
Conversation
I don't know why, but for some reason statistics.mean was overflowing in CI. See https://github.com/dask/distributed/actions/runs/3741526593/jobs/6351258185 I'm trying a naive implementation instead. It also happens to be faster and simpler. ```python In [1]: from statistics import mean In [2]: x = list(range(1000)) In [3]: %timeit mean(x) 196 µs ± 777 ns per loop (mean ± std. dev. of 7 runs, 1,000 loops each) In [4]: %timeit sum(x) / len(x) 4.82 µs ± 15.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each) ```
Unit Test ResultsSee test report for an extended history of previous test failures. This is useful for diagnosing flaky tests. 20 files + 8 20 suites +8 9h 0m 52s ⏱️ + 4h 41m 15s For more details on these failures, see this check. Results for commit 4e90750. ± Comparison against base commit 3ac8631. |
|
This is trivial enough and coming up enough in current PRs' CI that I plan to merge tomorrow US-time if there are no comments. |
statitics.mean
|
Woot. Thanks |
|
This is still an issue but now in the new code... Looks like
(the above screenshot is not reproducing, just a snapshot showing the data, I believe this is RSS memory, and the dtype) |
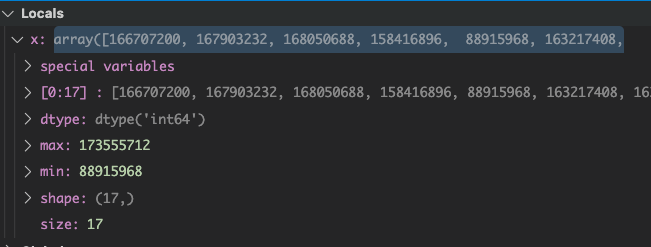
|
At the very least, this is giving exactly the same warning In [1]: import numpy as np
In [2]: sum(np.array([2**63-1, 1], dtype=np.int64)) |
I don't know why, but for some reason statistics.mean was overflowing in CI. See https://github.com/dask/distributed/actions/runs/3741526593/jobs/6351258185
I'm trying a naive implementation instead. It also happens to be faster and simpler.